Нейросеть Google произвольно стилизует изображения в реальном времени. Нейросеть картины
Нейросеть научилась рисовать картинки по текстовому описанию

He et al. / arXiv 2017
Разработчики из компании Microsoft создали новую порождающую состязательную нейросеть, которая умеет рисовать изображения на основе их краткого текстового описания. Система работает благодаря алгоритму, который учитывает важные детали описания, и подробно описана в препринте на arXiv.
Очень часто в основе создающих изображения алгоритмов лежат порождающие состязательные нейросети (также их называют генеративно-состязательными, GAN — generative adversarial networks) — разновидность искусственных нейронных сетей, состоящих из генератора и дискриминатора. Задача первого — создавать новые объекты, похожие на объекты из обучающей выборки, доступа к которой у него нет, а задача второго — решить, принадлежит ли сгенерированный объект к классу объектов из доступной ему обучающей выборки, и дать соответствующий сигнал генератору. На основе такого алгоритма создаются программы, которые умеют рисовать оригинальные произведения искусства, создавать трехмерные модели местности и даже превращать наброски в фотореалистичные портреты.
Разработчики из исследовательского отделения Microsoft под руководством Сяодуна Хэ (Xiaodong He) для создания изображений из текстового описания разработали новую разновидность GAN-нейросети: внимательную GAN (attentional GAN, AttGAN). В отличие от уже существующих алгоритмов, которые генерируют изображения из целого описания, превращая его в один вектор-предложение, новый алгоритм обращает внимание на детали: то есть оценивает каждое слово в описании и рисует изображение на их основе.

Архитектура AttGAN
He et al. / arXiv 2017
В результате нейросеть учится создавать достаточно реалистичные изображения на основе описаний. При обучении на базе данных COCO, содержащей текст и описание, работа новой нейросети превосходит уже существующие алгоритмы в точности на 170,25 процента, а при использовании базы данных CUB (она содержит изображения птиц) — на 14,14 процента.

Прилавок с бананами и киви
He et al. / arXiv 2017

Птичка черно-зеленого цвета с белым пузиком
He et al. / arXiv 2017

Закрученная домашняя паста с брокколи, морковью и луком
He et al. / arXiv 2017
Разработчикам, таким образом, удалось показать эффективность нового алгоритма создания изображений на основе описания и отдельно — эффективность добавления в нейросеть «внимательной» составляющей.
Недавно исследователи из Сеульского университета представили другую нейросеть, которая из текстового описания действия генерирует трехмерную модель его выполнения. Полученную модель затем можно использовать для того, чтобы заставить двигаться робота.
Елизавета Ивтушок
nplus1.ru
Нейросеть создаёт картины в стиле Ван Гога и Пикассо / Хабр

Компания Google недавно показала, как нейросеть может самостоятельно создавать произведения искусства. Попросту говоря, рисовать картины, утрируя существующие изображения.
Новый эксперимент, проведённый в университете Тюбингена (Германия) демонстрирует альтернативный алгоритм для нейросети: она правдоподобно подделывает художественный стиль Винсента Ван Гога, Пабло Пикассо, Эдварда Мунка и любых других художников. На вход для обработки подходят любые изображения. Пример работы алгоритма показан иллюстрациях вверху, где нейросеть обработала в разных стилях фотографию улицы в немецком городке.
Сгенерированные картины действительно красивы и, без сомнения, имеют высокую художественную ценность. Впрочем, это не означает, что оригиналы произведений великих мастеров прошлого упадут в цене. Скорее наоборот, ценность подлинников только возрастёт.
Нейронная сеть имеет 19 вложенных слоёв, а обработка исходного изображения происходит в несколько стадий. На каждой стадии в иерархии количество фильтров увеличивается, но при этом размер картинки становится меньше за счёт реализации механизма своеобразного даунсэмплинга.

Стилизация под конкретного автора происходит на этапах d, e.
Авторы научной работы считают главным достижением то, что удалось успешно отделить репрезентации контента и стиля в нейросети. Таким образом, ими можно управлять независимо друг от друга. Например, взять контент с одного изображения, а стиль — с другого. Именно это показано на самой первой иллюстрации, где одна фотография преобразуется в картины, выполненные в разном стиле.
Слои со стилем применяются или ко всему изображению, или фрагментарно. Вот как выглядит фотография города, если к ней применить стиль знаменитой картины «Композиция VII» Василия Кандинского.
Оригинал
Результат работы нейросети
habr.com
Нейросеть превратит каракули в картины художников

Alex J. Champandard
Разработчик Алекс Шампандар (Alex Champandard) на основе сверточной нейронной сети сделал программу, которая умеет создавать изображения в стилистике, задаваемой картинами художников. Исходный код программы Neural Doodle размещен на GitHub, научная работа, которая будет представлена на конференции nucl.ai Conference 2016, доступна на сайте arXiv.org.

Alex J. Champandard

Alex J. Champandard
Программа представляет собой скрипт Python doodle.py, который генерирует картины, принимая в качестве входных параметров три или четыре изображения. На «вход» подается образец стиля в виде картины и ее семантической карты, которая фактически представляет деление изображения на зоны сходной фактуры, и простой набросок того, что должно получиться. Такой набросок можно создать в простейшем графическом редакторе — разработчик называет их doodle или «каракули». Альтернативно, вместо собственного наброска, можно ввести второе изображение вместе с семантической картой, и тогда произойдет обмен стилями между двумя картинками.
«Входная» картина Ван Гога и ее семантическая карта снизу, рядом второе изображение и его семантическая карта
Alex J. Champandard
Сверточная нейронная сеть, в свою очередь, считывает стиль с картины художника и переносит их на пользовательский рисунок. Работа этой сети базируется на алгоритме, предложенном учеными из Майнцского университета. Для синтеза программа использует нейронную сеть VGG, отличающуюся особо большим числом скрытых слоев. Вводная картинка разбивается на части и ее характеристики, такие как цвет, зернистость, текстура считывается нейросетью. Затем она фактически сопоставляет стиль изображения с его содержанием (семантической картой) и после этого применяет стиль к другой семантической карте — наброску пользователя.Для работы NeuralDoodle необходимо иметь Python 3.4+ и ноутбук с хорошей видеокартой. Разработчик также выложил ссылку для скачивания обученной нейросети. На рендеринг одного изображения уходит приблизительно час (Шампандар использует компьютер MacBook Pro 2014).
В прошлом году в сети приобрел популярность Твиттер-бот @DeepForger, созданный этим же разработчиком. Он стилизует отправленные ему фотографии под картины.
Кристина Уласович
nplus1.ru
Создайте свои собственные “Нейронные Картины” с помощью Глубокого Обучения

Нейронные сети могут делать много разных вещей. Они могут понимать наши голоса, распознавать изображения и переводить речь, но знаете ли вы, что еще они умеют рисовать? Изображение сверху демонстрирует некоторые сгенерированные результаты применения нейронного рисования.
Сегодня я собираюсь познакомить вас с тем как это делается. Прежде всего, убедитесь, что у вас обновленная копия Ubuntu (14.04 — та, что использовал я). Вам необходимо иметь несколько гигов свободного пространства на жестком диске и в оперативной памяти, хотя бы не менее 6 GB (больше оперативки для больших выводимых разрешений). Для запуска Ubuntu как виртуальной машины, вы можете использовать Vagrant вместе с VirtualBox. Убедитесь, что у вас установлен git. Чтобы скачать и установить git, просто откройте терминал и выполните:
$ sudo apt-get install gitШаг 1: Установите torch7
Torch — это фреймворк для научных вычислений с широкой поддержкой алгоритмов машинного обучения. Torch является главным пакетом Torch7, где определены структуры данных для многомерных тензоров и математические операции для них. Дополнительно, он предоставляет много утилит для доступа к файлам, сериализации объектов произвольных типов и другие полезные утилиты. Запустите эти команды в терминале (вам может понадобиться использовать для них sudo):$ cd ~/ $ curl -s https://raw.githubusercontent.com/torch/ezinstall/master/install-deps | bash $ git clone https://github.com/torch/distro.git ~/torch --recursive $ cd ~/torch; ./install.sh Теперь нам надо обновить наши переменные окружения, запустите:$ source ~/.bashrcШаг 2: Установите loadcaffe
Выполните в терминале:$ sudo apt-get install libprotobuf-dev protobuf-compiler $ luarocks install loadcaffe Либо, если у вас возникают проблемы, попробуйте так:$ git clone [email protected]:szagoruyko/loadcaffe.git $ ~/torch/install/bin/luarocks install loadcaffe/loadcaffe-1.0–0.rockspecШаг 3: Установите neural-style
Это torch-реализация спецификации Нейронный Алгоритм Художественного Стиля Леона А. Гатиса, Александра С. Эккера и Маттиаса Бетге. Спецификация представляет алгоритм для комбинирования контента одного изображения со стилем другого изображения, используя сверточные нейронные сети. Сначала склонируйте neural-style с GitHub:$ cd ~/ $ git clone https://github.com/jcjohnson/neural-style.git Далее, скачайте модели нейронной сети:$ cd neural-style $ sh models/download_models.shШаг 4: Запускаем
Теперь убедитесь, что у вас есть хотя бы 6 GB оперативной памяти (если вы используете виртуальную машину, убедитесь, что выделили достаточное количество памяти для нее). Затем проверьте, работает ли нейронный стиль с помощью этой команды:$ th neural_style.lua -gpu -1 -print_iter 1 Заметьте, что вы выполняете это в режиме CPU, выполнение в режиме GPU выходит за рамки данной статьи.Чтобы увидеть инструкции о том, как использовать нейронный стиль, запустите:
$ th neural_style.lua ? Теперь давайте выполним тестовую команду, чтобы убедиться, что нейронные стили работают. Для начала убедитесь, что вы находитесь в директории нейронных сетей, если вы следовали всем инструкциям выше, вы должны быть в ~/neural-network, теперь запустите:th neural_style.lua -style_image examples/inputs/starry_night.jpg -content_image examples/inputs/golden_gate.jpg -gpu -1 -image_size 256 Заметьте, я ввел меньший размер изображения, чтобы обработка закончилась быстрее. Когда команда завершится, выходной файл, со стандартным именем out.png, будет расположен в той же директории.Результат
 golden_gate.jpg
golden_gate.jpg starry_night.jpg
starry_night.jpg
 out.png
out.png
habr.com
Нейросеть превратит наброски лиц в фотореалистичные портреты

Авторы проекта pix2pix представили систему, которая превращает созданные в графическом редакторе наброски лиц в портреты. В основе ее работы лежит использование нейросетей и технологий машинного обучения. О разработке рассказывает Motherboard, протестировать программу можно на отдельном сайте.
Одно из наиболее популярных направлений использования систем искусственного интеллекта — это работа с изображениями. Нейросети и алгоритмы машинного обучения используются для стилизации изображений под картины художников (переноса стиля), реалистичной деформации изображений, раскрашивания черно-белых фотографий, генерации шрифтов и многих других задач. В будущем подобные технологии могут быть использованы не только для развлечения, но и для помощи в работе дизайнерам, художникам, а также людям без специальных навыков рисования.
Программа, созданная участниками проекта pix2pix, использует модель условных порождающих состязательных сетей (conditional generative adversarial networks, cGAN) — одной из разновидностей GAN-нейросетей. Системы такого типа состоят из двух соревнующихся между собой компонентов: генеративного и различающего. «Генератор» старается обмануть «различитель», создавая такие образцы (в данном случае это будут портреты), которые его соперник не сможет отличить от настоящих, эталонных образцов. В итоге одна часть системы учится делать качественные подделки, а другая — их распознавать, что позволяет получить на выходе хороший результат и автоматически минимизировать функцию потерь.
То, что делает нейросеть, называется прямым переводом изображений (Image-to-image translation). Вместо того чтобы создавать изображения с нуля, система сопоставляет имеющиеся в ней данные с наброском пользователя. Фактически программа имеет некоторое абстрактное представление о том, как выглядят глаза, нос или рот и где они находятся, и это представление она переносит на скетч.

Скетч, превращенный нейросетью в портрет
Несмотря на то, что алгоритм должен создавать фотореалистичные изображения, его работа пока далека от идеала. Например, иногда нейросеть плохо распознает волосы или линию рта и сгенерированные портреты порой выглядят пугающе. Вероятно, для достижения лучших результатов необходимо больше обучающих данных.

Несколько месяцев назад другой автор, использующий ту же модель, что и pix2pix, продемонстрировал похожую систему — генератор котов, который также превращает скетчи животных в реалистичные изображения. Разработчик Алекс Шампандар, в свою очередь, также создал программу, которая превращает наброски в картины в стиле определенных художников.
Кристина Уласович
nplus1.ru
Нейросеть Google произвольно стилизует изображения в реальном времени / Хабр
 Нейросеть от Google накладывает на фотографию любой из 32 обученных стилей (здесь показаны пять). Программа нетребовательна к железу и памяти. Код опубликуют в ближайшее время
Нейросеть от Google накладывает на фотографию любой из 32 обученных стилей (здесь показаны пять). Программа нетребовательна к железу и памяти. Код опубликуют в ближайшее времяСинтез текстур с переносом стиля с одного изображения на другое — известная техника, которой 15 лет. Впервые она описана в статье «Аналогии по изображению» группы исследователей из Microsoft Research для конференции SIGGRAPH 2001, а также в статье «Подбивка изображения для текстурного синтеза и переноса» от Mitsubishi Electric Research и Калифорнийского университета в Беркли в том же 2001 году. Сейчас трудно сказать, какая из них появилась раньше.
В 2015 году техника получила вторую жизнь, когда к синтезу изображений с переносом стиля подключились нейросети. Это случилось после выхода научной работы «Нейроалгоритм художественного стиля» Гэтиса, Эккера и Бетге из университета Эберхарда-Карла в Тюбингене, Германия (статья на Geektimes). Работа настолько впечатляющая, что описанный алгоритм вскоре реализовали в нескольких компьютерных программах для потребительского рынка, в том числе в мобильных приложениях вроде российского Prisma (июнь 2016-го). Работа Гэтиса, Эккера и Бетге хороша тем, что авторы обучили нейросеть на существующих работах известных художников: Винсента Ван Гога, Пабло Пикассо, Эдварда Мунка и других. При этом нейросеть можно продолжить обучать на других наборах данных, так что это универсальный инструмент. Именно такая нейросеть работает на сервере Prisma и других компаний, которые распространяют мобильные приложения для стилизации пользовательских фотографий.
Свёрточная нейросеть Гэтиса, Эккера и Бетге создана на основе 19-слойной VGG-нейросети Симоняна и Зиссермана, а обработка исходного изображения происходит в несколько стадий. На каждой стадии в иерархии количество фильтров увеличивается. Стилизация под конкретный стиль происходит на первых этапах «даунсэмплинга» (широкие мазки, кубистские паттерны и т.д.), а последние слои нейросети обрабатывают оригинальное изображение, чтобы объекты оставались узнаваемыми (d и e на схеме). Нейросеть начинает работу со случайной позиции (или с исходного изображения) до тех пор, пока результат не удовлетворяет заданным требованиям.
В нейросети разделены друг от друга репрезентации контента и стиля. Таким образом, ими можно управлять независимо друг от друга. Например, взять контент с одного изображения, а стиль — с другого.
 Примеры стилизации изображений в нейросети Гэтиса, Эккера и Бетге
Примеры стилизации изображений в нейросети Гэтиса, Эккера и Бетге
Оригинальное изображение: Старый город в Тюбингене
Образец стиля: картина «Голова клоуна» (1907-1908), Жорж Руо, стиль: экспрессионизм
Результат работы нейросети
Эту работу считают фундаментальным прорывом в технологиях глубинного обучения, потому что это первая концептуальное доказательство передачи художественного стиля через нейросеть. То, что считалось художественным видением, авторским стилем и жанром искусства, успешно поддаётся формализации и усваивается нейросетью. Искусственный интеллект впервые освоил настоящее творчество.
На идее разделения стиля и содержания картины созданы разнообразные нейросети, в том числе для генерации пугающих изображений и для генерации порнокартинок.
К сожалению, у нейросети Гэтиса, Эккера и Бетге есть недостаток: такая нейросеть слишком требовательна к вычислительным ресурсам. Это стало понятно после выхода первых демо-приложений, которые несколько минут обрабатывались на сервере.
В последующих работах, в том числе российских специалистов, нейросеть была значительно оптимизирована за счёт ограничения функциональности. В итоге, оптимизация дошла до такой степени, что вместо нескольких минут стилизация фотографии стала происходить практически мгновенно. Так что появилась возможность стилизовать даже видео в реальном времени!
Но у подобной стилизации есть обратная сторона медали. Сверхбыстрая стилизация возможна только если за образец берётся одно изображение. Это ограничение оригинального алгоритма, ведь тот не привязан к одному стилю. Другими словами, если вы хотите сделать систему, способную передавать 100 разных стилей, то вам придётся предварительно обучать 100 разных нейросетей.
Сейчас компания Google внесла свою лепту в эти исследования. 24 октября 2016 года сотрудники Google Brain Team опубликовали статью с описанием алгоритма, который работает так же быстро, как и предыдущие, но при этом в единой универсальной нейросети, которая может накладывать любые усвоенные стили.
По словам разработчиков, их алгоритм прост в реализации и не выдвигает высоких требований к оперативной памяти. Более того, после обучения на нескольких стилях он способен сочетать несколько стилей одновременно и работает в реальном режиме времени. Например, вот фотография того же Старого города в Тюбингене, на которую наложено четыре стиля одновременно.

Исследователи считают, что их работа открывает новые возможности по творческому использованию нейросети стилизации. В ближайшее время в блоге Magenta они обещают опубликовать исходный код программы для TensorFlow, так что каждый сможет запустить демо на своём компьютере.
Более подробно о стилизации изображений в нейросети рассказано в научно-популярном видео. Его записали две сотрудницы Nat и Lo в 20% своего рабочего времени, которые компания Google выделяет для проектов на свой выбор.
habr.com
Синтез изображений с помощью глубоких нейросетей. Лекция в Яндексе
Пусть в блоге Яндекса на Хабрахабре эта неделя пройдет под знаком нейронных сетей. Как мы видим, нейросети сейчас начинают использоваться в очень многих областях, включая поиск. Кажется, что «модно» искать для них новые сферы применения, а в тех сферах, где они работают уже какое-то время, процессы не такие интересные.Однако события в мире синтеза визуальных образов доказывают обратное. Да, компании еще несколько лет назад начали использовать нейросети для операций с изображениями — но это был не конец пути, а его начало. Недавно руководитель группы компьютерного зрения «Сколтеха» и большой друг Яндекса и ШАДа Виктор Лемпицкий рассказал о нескольких новых способах применения сетей к изображениям. Поскольку сегодняшняя лекция — про картинки, то она очень наглядная.
Под катом — расшифровка и большинство слайдов. Добрый вечер. Я сегодня буду говорить про сверточные нейросети и буду предполагать, что большинство из вас провели последние четыре года не на необитаемом острове, поэтому что-то про сверточные глубокие нейросети слышали, и знаете примерно, как именно они обрабатывают данные.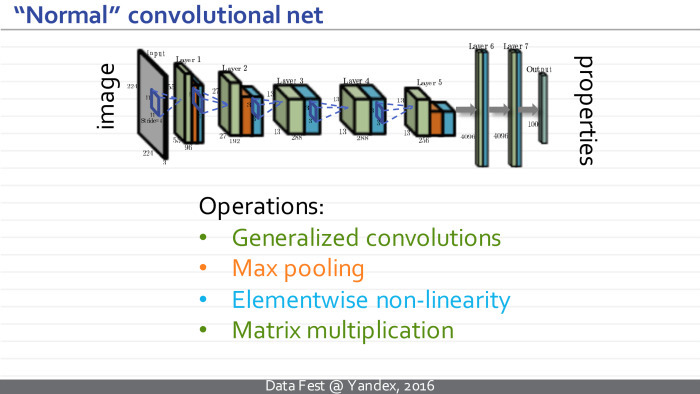
Поэтому я потрачу первые два слайда, чтобы рассказать, как именно они применяются к изображениям. Они представляют собой некоторые архитектуры — сложные функции с большим количеством настраиваемых параметров, где элементарные операции относятся к определенным типам, таким как обобщенные свертки, уменьшение размера изображения, так называемый пулинг, поэлементная нелинейность, применяемая к индивидуальным измерениям, и умножение на матрицу. Такая сверточная нейросеть берет последовательность этих операций, берет некоторое изображение, например эту кошечку.
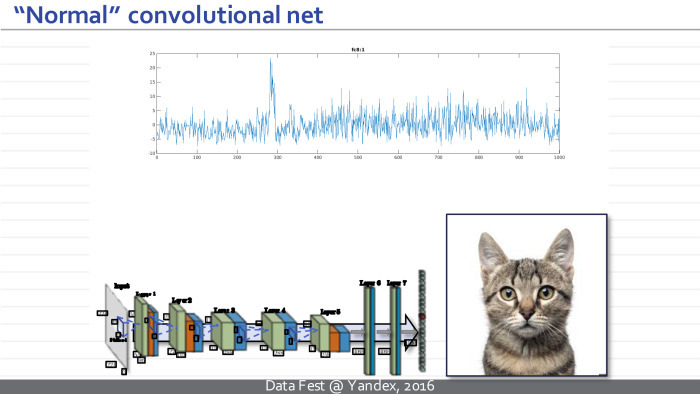
Дальше она преобразует подобный набор из трех изображений в набор из ста изображений, где каждый прямоугольничек представляет себе действительно значимое изображение, заданное в MATLAB-формате.
Дальше применяются некоторые нелинейности, и с помощью операций обобщенной свертки считается новый набор изображений. Происходит несколько итераций, и в какой-то момент такой набор изображений преобразуется в многомерный вектор. После еще ряда умножений на матрицу и поэлементных нелинейностей этот вектор превращается в вектор свойств входного изображения, до которого нам хотелось добраться, когда мы обучали нейросеть. Например, этот вектор может соответствовать нормированным вероятностям или ненормированным величинам, где большие значения говорят о том, что тот или иной класс объектов присутствует на изображении. В данном примере горб наверху соответствует разным породам кошек, и нейросеть думает, что это изображение содержит кошку той или иной породы.
Нейросети, которые берут картинки, обрабатывают их в таком порядке и получают подобные промежуточные представления, я буду называть нормальными, обычными или традиционными сверточными сетями.
Но говорить я сегодня буду главным образом не про них, а про новый популярный класс моделей, который я буду называть перевернутыми или развернутыми нейросетями.
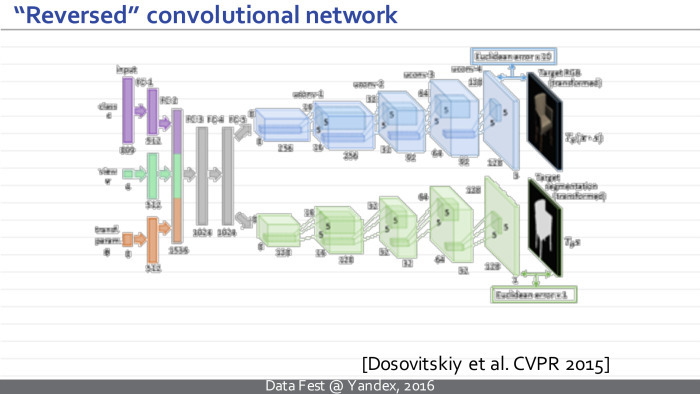
Вот пример такой перевернутой нейросети. Это хорошо известная модель фрайбургской группы, Досовицкого и коллег, которая обучена брать некоторый вектор параметров и синтезировать изображение, которое им соответствует.
Более конкретно, на вход этой нейросети подается вектор, который кодирует класс, определенный тип стула, и еще один вектор, который кодирует геометрические параметры камеры. На выходе эта нейросеть синтезирует изображение стула и маску, отделяющую стул от фона.
Как видите, отличие такой развернутой нейросети от традиционной — в том, что она всё делает в обратном порядке. Изображение у нас теперь не на входе, а на выходе. И представления, которые возникают в этой нейросети, сначала являются просто векторами, а в некоторый момент превращаются в наборы изображений. Постепенно изображения комбинируются друг с другом с помощью обобщенных сверток, и на выходе получаются картинки.
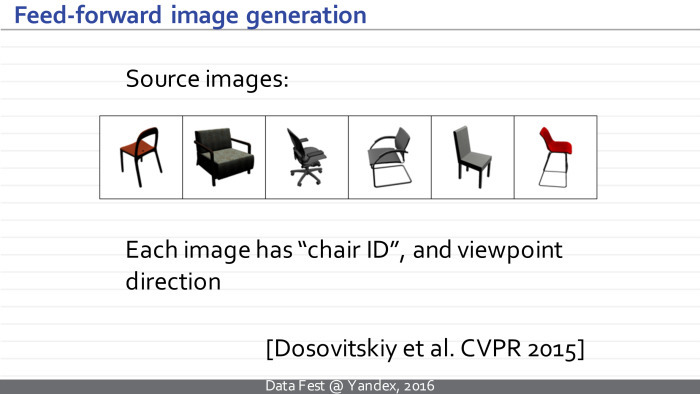
В принципе, нейросеть, указанная на предыдущем слайде, была обучена на базе синтетических изображений стульев, которые были получены из нескольких сотен CAD-моделей стульев. Каждое изображение снабжено меткой класса стула и параметрами камеры, соответствующей данному изображению.
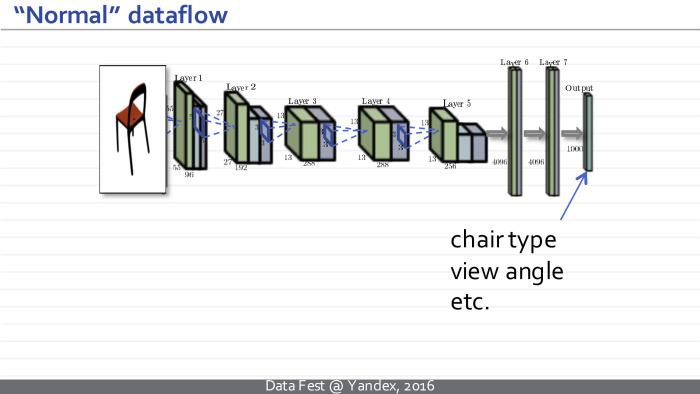
Обычная нейросеть возьмет на вход изображение стула, предскажет нам тип стула и характеристики камеры.
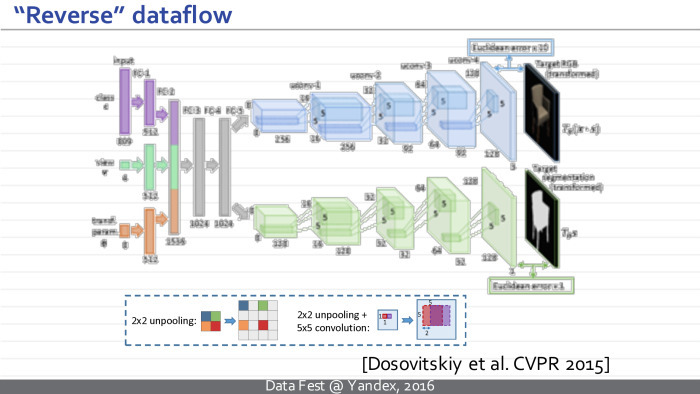
Нейросеть Досовицкого всё делает наоборот — генерирует изображение стула на выходе. Надеюсь, разница понятна.
Интересно, что компоненты перевернутой нейросети почти в точности повторяют компоненты обычной нейросети. Единственная новизна и новый модуль, который возникает, — модуль обратного пулинга, анпулинга. Эта операция берет картинки меньшего размера и преобразует их в картинки большего размера. Такое можно делать многими способами, которые работают примерно одинаково. Например, в их статье они брали карты маленького размера, просто вставляли между ними нули, дальше обрабатывали подобные изображения.
Данная модель оказалась очень популярной, вызвала много интереса и последующих работ. В частности, оказалось, что такая нейросеть работает очень хорошо, несмотря на кажущуюся необычность, экзотичность и неестественность такой идеи — развернуть нейросеть вверх ногами, слева направо. Она способна не только к заучиванию обучающего множества, но и к очень хорошим обобщениям.

Они показали, что такая нейросеть может интерполировать между двумя моделями стульев и получать модель как смесь стульев, которые были в обучающем множестве, которые нейросеть никогда не видела. И тот факт, что эти смеси выглядят как стулья, а не как произвольные смеси пикселей, говорит о том, что наша нейросеть очень хорошо обобщается.
Если задать себе вопрос, почему это так хорошо работает, то есть несколько ответов. Меня больше всего убеждают два. Первый: почему должно работать плохо, если хорошо работают прямые нейросети? И прямые, и развернутые сети используют одно и то же свойство натуральных изображений о том, что их статистика локальная и внешний вид кусочков изображений не зависит от того, на какую часть глобального изображения мы смотрим. Такое свойство позволяет нам разделять, переиспользовать параметры внутри сверточных слоев обычных сверточных нейросетей, и это же свойство используют развернутые сети, используют успешно — оно дает им возможность относительно небольшим количеством параметров обрабатывать и заучивать большие объемы данных.
Второе свойство, менее очевидное и отсутствующее в прямых нейросетях: при обучении развернутой сети у нас есть гораздо больше обучающих данных, чем кажется на первый взгляд. Каждая картинка содержит в себе сотни тысяч пикселей, а каждый пиксель, хоть он и не является независимым примером, так или иначе накладывает ограничения на параметры сети. Как следствие, подобную развернутую нейросеть можно эффективно обучить по множеству изображений, которое будет меньше, чем было бы нужно для хорошего обучения прямой сети похожей архитектуры с тем же количеством параметров. Грубо говоря, мы можем обучить хорошую модель для стульев, используя тысячи или десятки тысяч изображений, но не миллион.
Сегодня я хотел бы рассказать про три текущих проекта, связанных с развернутыми нейросетями или, по крайней мере, нейросетями, выдающими на выходе изображение. Я вряд ли смогу углубиться в подробности — они доступны по ссылкам и в статьях нашей группы — но надеюсь, такой пробег по верхам продемонстрирует вам гибкость и интересность данного класса задач. Может быть, он приведет к каким-то идеям о том, как еще можно использовать нейросети для синтеза изображений.

Первая идея посвящена синтезу текстур и стилизации изображений. Я буду говорить про класс методов, совпадающий с тем, что происходит в Prisma и похожих приложениях. Все это развивалось параллельно и даже слегка опережая Prisma и похожие приложения. Используются в ней эти методы или нет — мы наверняка не знаем, но у нас есть какие-то предположения.
Начинается все с классической задачи текстурного синтеза. Этой задачей люди в компьютерной графике занимались десятилетиями. Совсем коротко она формулируется так: дан образец текстуры и нужно предложить метод, который сможет по данному образцу генерировать новые образцы той же текстуры.
Задача синтеза текстур во многом упирается в задачу сравнения текстур. Как понять, что эти два изображения соответствуют похожим текстурам, а эти два — непохожим? Достаточно очевидно, что какие-то простые подходы — например, сравнить три изображения попиксельно попарно или посмотреть на гистограммы — не приведут нас к успеху, потому что схожесть у этой пары окажется такой же, как и у этой. Многие исследователи ломали голову над тем, как определить меры схожести текстур, как определить некий текстурный дескриптор, чтобы какая-то простая мера в таких продвинутых дескрипторах хорошо бы говорила, являются текстуры похожими или нет.

Полтора года назад группой в Тюбингене был достигнут некоторый прорыв. На самом деле, они обобщили более ранний метод на основе статистики вейвлетов, которую они заменили на статистику активаций. Она создает изображения и вызывает в некоторой глубокой предобычной сети.
В своих обычных экспериментах они брали большую глубокую нейросеть, обученную для классификации. В дальнейшем оказалось, что тут возможны варианты: сеть даже может быть глубокой со случайными весами, если они были инициализированы определенным образом.
Так или иначе, статистика определяется так. Возьмем изображение, пропустим его через первые несколько сверточных слоев нейросети. На этом слое получим набор карт, изображений Fl(t). t — образец текстуры. Его набор карт изображений — на l-слое.
Дальше мы считаем статистику текстур — она должна как-то исключать из себя параметры, связанные с пространственным расположением того или иного элемента. Естественный подход — взять все пары карт в данном представлении. Мы берем все пары карт, считаем все попарные скалярные произведения между этими парами, берем i-тую карту и j-тую карту, дальше k-тый индекс пробегает все возможные пространственные положения, мы считаем подобное скалярное произведение и получаем i, j коэффициент, член матрицы Грама. l-матрица Грама, посчитанная таким образом, описывает нашу текстуру.
Дальше, когда надо сравнить, похожи ли два изображения как текстуры, мы просто берем некоторый набор слоев: это может быть один слой — тогда данная сумма включает в себя один член. Или можем взять несколько сверточных слоев. Сравниваем матрицы Грама, посчитанные таким образом для этих двух изображений. Сравнивать их мы можем просто поэлементно.
Оказывается, такая статистика очень хорошо говорит о том, похожи две текстуры или нет, — лучше, чем всё, что было предложено до работы на слайде.

Теперь, когда у нас есть очень хорошая мера, позволяющая сравнивать текстуры, мы можем взять некоторое случайное приближение, случайный шум. Пусть текущее изображение обозначается как х и есть некий образец t. мы будем пропускать наше текущее состояние через нейросеть, смотреть на его текущую матрицу Грама. Дальше с помощью алгоритма обратного распространения — понимать, как надо изменить текущее распространение, чтобы его матрицы Грама внутри нейросети стали чуть более похожи на матрицы Грама образца, который мы хотим синтезировть. Постепенно наше шумное изображение превратится в набор камней.

Работает это очень хорошо. Вот пример из их статьи. Справа пример, который мы хотим повторить, а слева синтезированная текстура. Главная проблема — время работы. Для небольших изображений оно составляет много секунд.
Идея данного подхода — радикально ускорить процесс генерации текстур через использование перевернутой нейросети.
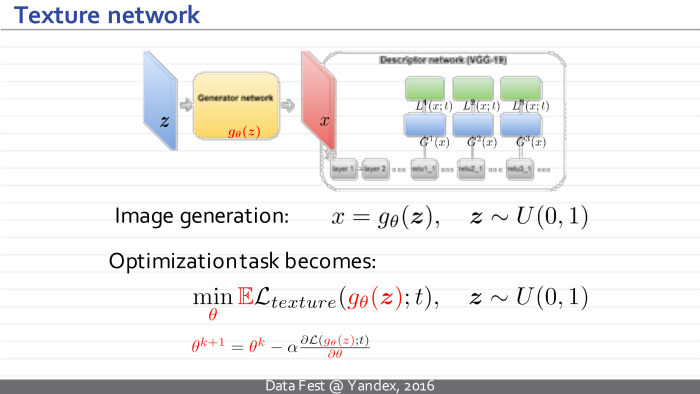
Было предложено обучить для данного текстурного образца новую развернутую нейросеть, которая бы принимала на вход некоторый шум и выдавала новые образцы текстуры.
Таким образом х — который в предыдущем подходе был некоторой независимой переменной и мы ей манипулировали, пытаясь создать текстуры, — теперь становится зависимой переменной, выходом новой нейросети. У нее свои параметры θ. Идея в том, чтобы перенести обучение в отдельную стадию. Теперь мы берем и учим нейросеть, настраивая ее параметры так, чтобы для произвольных векторов шума получающиеся изображения имели матрицы Грама, соответствующие нашему образцу.
Функции потери остаются теми же, но теперь у нас появляется дополнительный модуль, который мы можем предобучить заранее. Минусом является то, что теперь есть долгосрочная стадия обучения, но плюс в следующем: после обучения мы можем синтезировать новые образцы текстуры просто путем синтеза нового вектора шума, пропуска его через нейросеть, и это занимает несколько десятков миллисекунд.
Оптимизация нейросети тоже производится методом стохастического градиентного спуска, а наше обучение происходит так: мы синтезируем вектор шума, пропускаем его через нейросеть, считаем матрицы Грама, смотрим расхождения и обратным распространением через весь этот путь понимаем, как именно надо поменять параметры нейросети.
Здесь некоторые детали архитектуры, я их пропущу. Архитектура полностью сверточная, в ней нет полносвязных слоев, и количество параметров невелико. Такая схема, в частности, не позволяет сети просто заучить предоставленный ей пример текстуры так, чтобы выдавать его снова и снова.

Пример работы архитектуры. Слева заданный образец, а справа три примера, которые каждая из трех нейросетей в верхнем, нижнем и среднем ряду выдает для данных образцов. И это происходит за несколько десятков миллисекунд, а не за секунды, как раньше. Особенность архитектуры позволяет нам синтезировать текстуры произвольного размера.

Мы можем сравнить между собой результат изначального подхода, требовавшего оптимизации, и нового подхода. Мы видим, что качество получаемых текстур сравнимо.
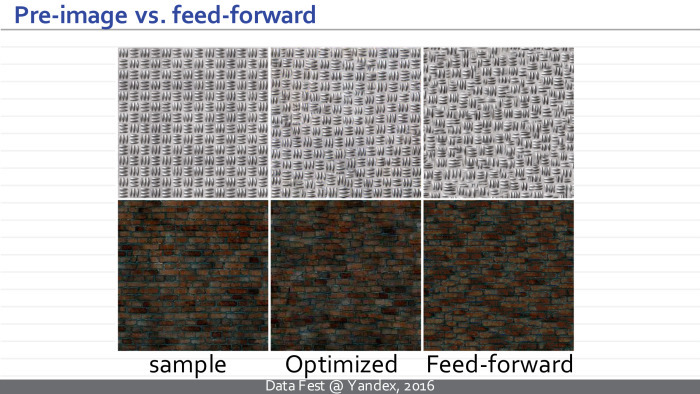
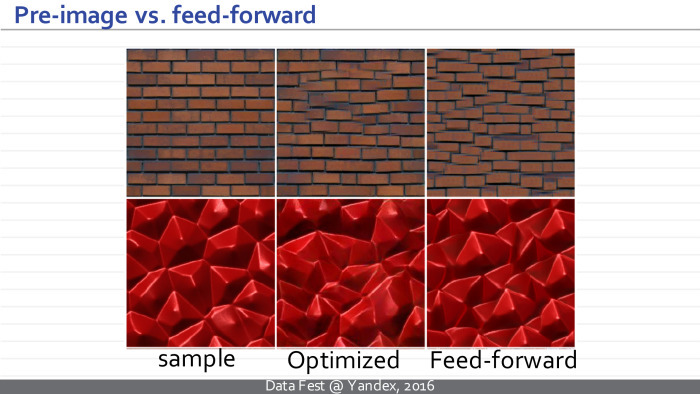
Посередине приведен образец текстуры, полученной с помощью метода Готисса (неразборчиво — прим. ред.), оптимизации, а справа примеры текстур, выдаваемых нейросетью просто путем преобразования вектора шума.
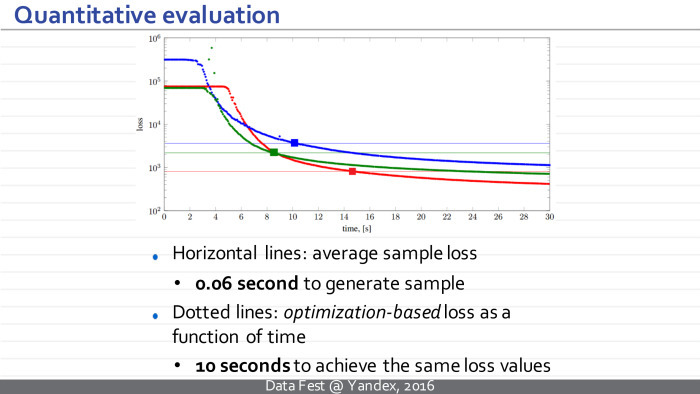
На самом деле то, что происходит, можно проинтерпретировать так: получающаяся нейросеть является псевдооптимизатором и для некоторых векторов шума генерирует некоторое хорошее решение, которое потом может быть улучшено, например, с помощью оптимизационного подхода. Но обычно этого не требуется, потому что получающееся решение визуально имеет чуть большую функцию потерь, но по визуальному качеству не сильно уступает или превосходит то, что можно получить, продолжая оптимизацию.
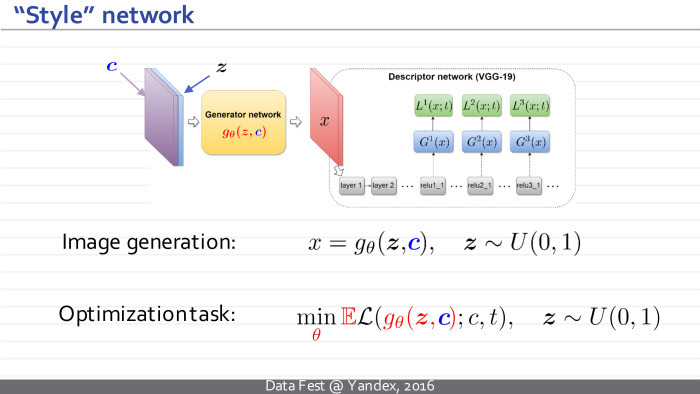
Что интересно, данный подход вполне можно обобщить для стилизации изображений. Речь идет о процессах, когда по заданной фотографии и заданному образцу визуального стиля строится новое изображение, имеющее то же содержимое, что и фотография, и тот же визуальный стиль, что и образец стиля.
Единственное изменение: наша нейросеть будет принимать на вход не только вектор шума, но и изображение, которое нужно стилизовать. Она обучается для произвольного примера стиля.

В исходной статье не получилось построить архитектуру, которая давала бы результаты, сравнимые по качеству с оптимизационным подходом. Позже Дмитрий Ульянов, первый автор статьи, нашел архитектуру, позволившую радикально улучшить качество и добиться качества стилизации, сравнимого с оптимизационным подходом.
Здесь сверху — фотография и пример визуального стиля, а внизу результат стилизации такой нейросети, требующий нескольких десятков миллисекунд, и результат оптимизационного метода — который, в свою очередь, требует многосекундной оптимизации.

Можно обсуждать и качество, и то, какая стилизация более успешна. Но, думаю, в данном случае это уже неочевидный вопрос. В указанном примере мне лично больше нравится левый вариант. Возможно, я предвзят.

Здесь, наверное, скорее правый.

Но в таком варианте получается достаточно неожиданный для меня результат. Кажется, что подход, основанный на перевернутой развернутой нейросети, добивается лучшей стилизации, в то время как оптимизационный метод застревает где-то в плохом локальном минимуме или где-то на плато — то есть не может до конца стилизовать фотографию.
К стилизации еще вернемся. Второй проект связан с нейросетью, которая решает следующую задачу. Нам хотелось построить сеть, способную взять фотографию лица человека и перенаправить его взгляд на этой фотографии.
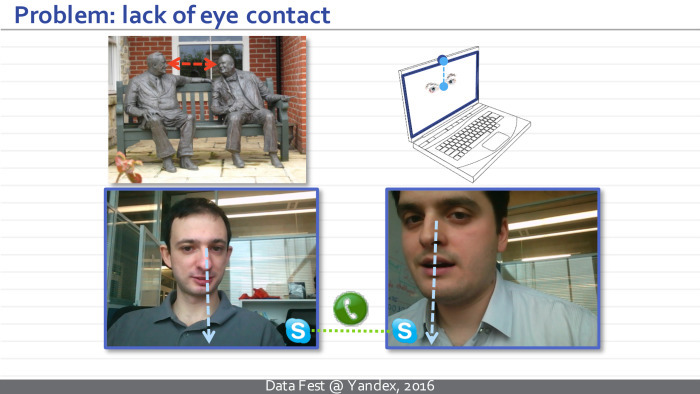
Зачем нам понадобилось решать такую экзотическую задачу? Оказывается, есть по крайней мере два приложения, где она актуальна. Главное для нас — задача улучшения зрительного контакта при видеоконференциях. Наверное, многие замечали, что когда вы разговариваете по Skype или другому видеоконференционному сервису, то не можете смотреть с собеседником друг другу в глаза, потому что камера и лицо собеседника разнесены по местоположению.
Еще одно применение — постобработка кинофильмов. У вас есть какая-то суперзвезда, у которой минута съемки стоит миллион долларов. Вы отсняли дубль, а эта суперзвезда посмотрела не туда. И теперь надо или переснять дубль, или — подредактировать направление взгляда.

Чтобы решить такую задачу, мы собрали большое количество последовательностей. В рамках них мы фиксировали положение головы, освещение — всё, кроме направления взгляда. Протокол был такой, что мы могли отслеживать, куда человек смотрит. Каждый кадр анонсирован соответствующим направлением взгляда.

Это позволило нам извлекать из подобного набора данных пары примеров, для которых мы знаем: единственное отличие между изображениями слева и справа — направление взгляда. Например, здесь в каждом случае отличие составляет 15 градусов в вертикальном направлении.
Мы практически перешли от такой сложной задачи к классической задаче обучения с учителем. У нас есть пример слева, и нам нужно сгенерировать пример справа. К сожалению, просто решать эту задачу с помощью черного ящика, как говорил Сергей, не получается. Мы много раз пробовали черный ящик, даже темно-серый ящик. Поскольку у нас вход и выход имеют довольно сложную структуру, а обучающих данных довольно много, мы долго мучили людей. Решение с помощью черного ящика не работает. Нужно использовать некую специфику задачи, а именно — то, что правое изображение может быть достаточно неплохо приближено левым изображением после некоторой нежесткой деформации.
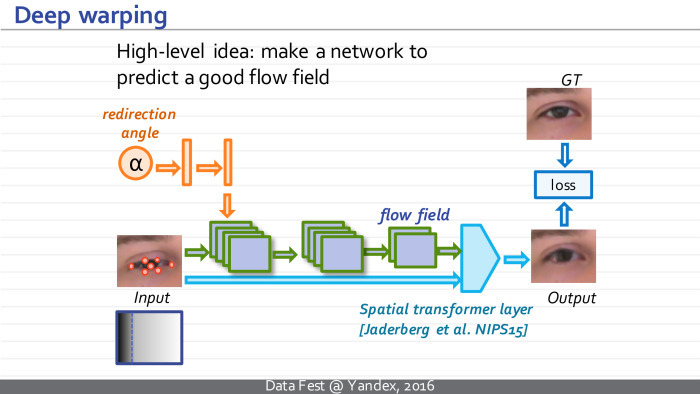
Была построена нейросеть, которая принимает на вход изображение слева, а также берет положение особых точек глаза на данном изображении. При этом изображение кодируется тремя картамиЕ красной, зеленой и синей. Каждая особая точка тоже кодируется картой. Дальше она принимает на вход угол, на который мы хотим перенаправить взгляд на картинке, и строит поле искажения, деформации. Потом такое поле применяется к входному изображению дифференцируемым образом с помощью spatial transformer layer. Он сейчас есть, например, в torch и многих других библиотеках.
Для каждого примера в обучающей выборке мы знаем, как он должен выглядеть после деформации. Поэтому мы можем сравнить то, что получилось, и то, что должно было получиться, посчитать функции потери и после этого настроить параметры нашей нейросети со стохастически градиентным спуском так, чтобы получающийся результат был как можно ближе к GT.
После следует некое усложнение модели. Первый уровень считает некое грубое поле смещений, второй — уточняет такое поле, а третий — моделирует те преобразования, которые невозможно моделировать с помощью ворпинга. Скажем, при перенаправлении взгляда вверх обычно характерным образом меняется освещенность — потому что источник света обычно расположен сверху, и такое нельзя смоделировать с помощью ворпинга. Соответственно, добавляется модуль, затемняющий или осветляющий некоторые пиксели.
Все три модуля тренируются вместе с начала до конца в процессе единого стохастического спуска. Затем мы можем применять обычную сеть к новым изображениям, которые она никогда не видела, и получать примерно такие результаты. В данном случае мы каждый раз берем статическую картинку, берем фиксированную нейросеть и, подавая разные углы на вход, можем получать подобные забавные видео.
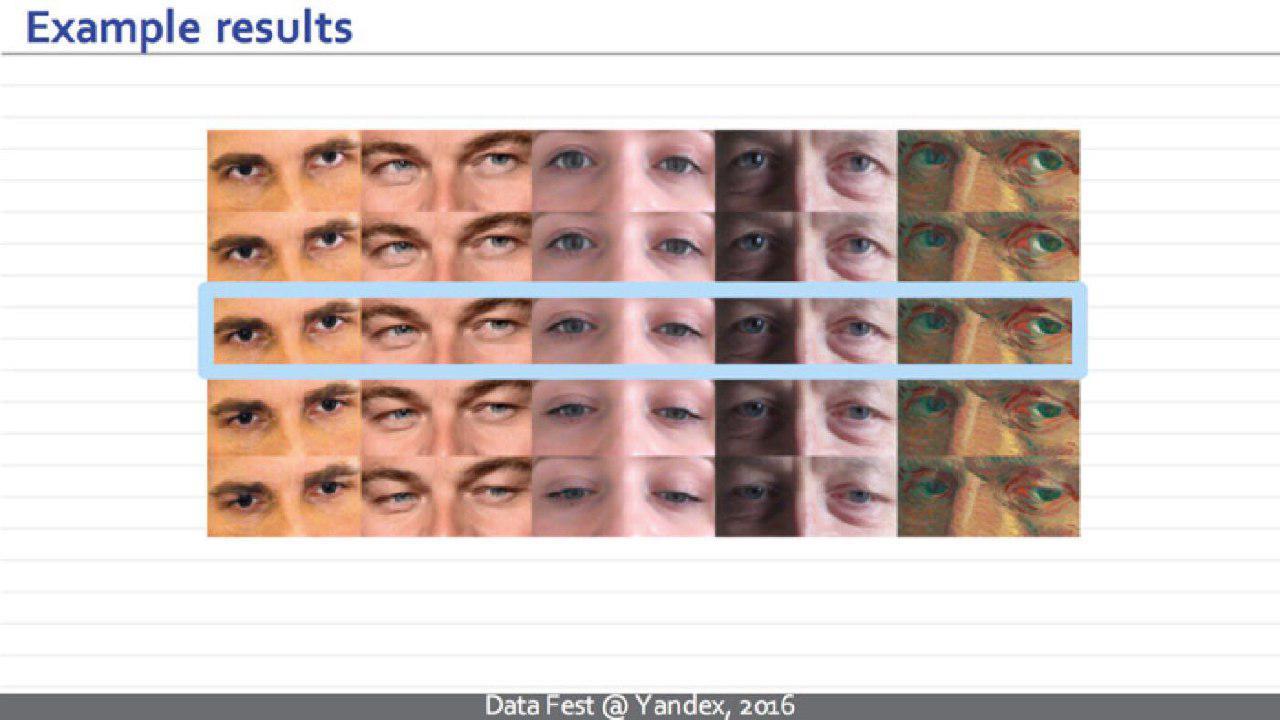
Вот еще статические примеры. Такая нейросеть прибавляет плюс-минус 15 градусов в вертикальном направлении. Ни один из этих людей не представлен в тренировочном множестве.

Пример для горизонтального перенаправления.

Еще набор примеров. Мы рады сказать, что готовится к выпуску веб-демо, куда каждый сможет подгрузить картинку и посмотреть на результаты.
Наконец, третья система. Это совсем свежая статья, первый раз про нее рассказываю. Она посвящена нейросетям, которые учат визуальные маркеры.
Визуальные маркеры нас окружают и становятся всё более заметными. Речь идёт об изображениях, в которых компьютером — и для компьютера же — зашита некая информация. Такие изображения возникают в реальном человеческом мире и обладают некоторыми нежелательными свойствами. Они, например, эстетически неидеальны. Я говорю о таких примерах, как QR-коды, бар-коды.
Еще они неидеальны с концептуальной точки зрения в том смысле, что процесс дизайна маркера и процесс написания распознавателя маркера разделены. Сначала кто-то придумал, как определить маркер, как маркер должен быть устроен, а потом для него уже пишется распознаватель.
Наша идея — объединить процесс создания маркера и процесс создания распознавателя маркера в единый оптимизационный процесс и параллельно добиться некоторых эстетических свойств получаемых маркеров.
Мы строим некоторую цепочку нейросетей. Первая нейросеть называется синтезатором. Синтезатор берет на вход последовательность бит, которую мы хотим закодировать, и, являясь обычной перевернутой развернутой нейросетью, превращает ее в картинку. Это точно такая же нейросеть, как та, о которой я говорил в начале доклада.
Затем вторая нейросеть берет полученный маркер и симулирует процесс его распечатывания, вешания на стену и фотографирования. Иными словами, она превращает такой маркер как компьютерный файл в маркер-фотографию на стене. Это моделируется путем нескольких преобразований — таких как наложение на фон, фильтрация, блюр и т. д.
Такая нейросеть не содержит настраиваемых параметров. Вместо этого в процессе обучения мы синтезируем случайные параметры, и она таким образом преобразует изображения.
Последняя нейросеть — стандартная и прямая. Она принимает на вход картинку и пытается установить закодированное изображение. Мы можем обучать всю цепочку, параметры синтезатора и параметры распознавателя вместе, путем минимизации разницы между входной и выходной строчками.
Мы можем посмотреть, какие именно маркеры нашей системы выучатся. Главная идея, что синтезатор будет адаптирован под распознаватель, а распознаватель — под синтезатор.

На данном слайде есть примеры картинок. Каждая шестерка соответствует набору маркеров, которые, в свою очередь, соответствуют случайным битовым последовательностям. Разумеется, они отличаются в зависимости от количества бит, от того, насколько сильные искажения вносит распознаватель, черно-белые мы хотим маркеры или цветные.
В целом, они имеют интересную регулярную структуру — какую-то гармоническую, синусоидальную.
Забавно их сравнить с подобными визуальными иллюзиями для сетей. Их многие группы предложили, чтобы вызывать в фиксированных предобученных распознавателях некоторые респонсы.
Затем мы можем распечатать полученные маркеры, сфотографировать их и убедиться, что наша нейросеть достаточно хорошо распознает закодированные в них биты.
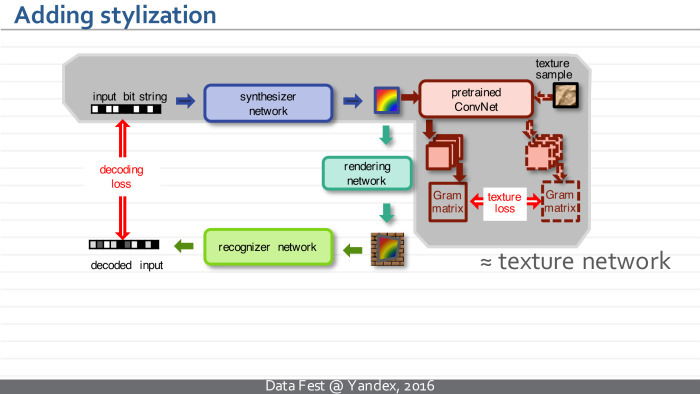
Что самое интересное, дальше мы можем в наше обучение добавить новый модуль, который будет смотреть на получающиеся маркеры и делать их похожими на примеры некоторых текстур — в точности как я рассказывал во второй части доклада.

Все это происходит в рамках единого оптимизационного процесса и позволяет нам синтезировать маркеры, подобные тем, что на слайде. Слева задан образец текстуры, справа — образцы маркеров для случайных последовательностей. Интересный факт: глядя на эти маркеры, можно увидеть, что некоторые камушки не меняются от маркера к маркеру, а некоторые части маркера меняются в зависимости от бита. Такая ситуация в точности соответствует тому, что происходит в QR-коде, где у вас есть по углам четыре якоря, которые не меняются и используются для локализации, и есть переменная часть кода. Эта нейросеть выучила такой эффект — он не зашит в ее архитектуру.

Еще два примера. Нейросеть учится письменности.
Нейросеть учится на фотографии храма Василия Блаженного. Нам показалось, что было бы здорово, если бы огромные QR-коды, налепленные на стенах в Москве, заменились бы чем-то более интересным.

Я представил три статьи. Хотел бы поблагодарить своих соавторов. Это их результаты, и в данной области есть много чего нерешенного. Главная нерешенная задача, на мой взгляд, — построение нейросетей, способных синтезировать большие новые изображения. Сейчас многие умеют синтезировать по фотографии версию Ван Гога, но я не знаю нейросетей, которые могут по изображению Ван Гога синтезировать исходную фотографию. Это интересная нерешенная задача. Спасибо.
habr.com







