Чтобы распознавать картинки, не нужно распознавать картинки. Распознаватель картин
Распознавание текста онлайн — ТОП-9 сервисов
Распознавание текста с картинки, OCR (optical character recognition), то есть превращение картинки в текст доступно бесплатно на многих сайтах в режиме онлайн. Но везде свое качество и свои ограничения на количество распознаваемых картинок.
Я проверила с десяток онлайн-сервисов и составила рейтинг лучших.
Для примера распознавала фотографию документа, который есть у каждого – свидетельство ИНН физического лица (разрешением 1275×1750 пикселей).
В Google можно распознавать неограниченное количество картинок, лишь бы они поместились на Google Drive. Нужно просто открыть картинку с Google диска с помощью Google Документов, и она автоматически распознается.
| Входные форматы | PDF , JPEG, PNG, GIF |
| Выходные форматы | Word, Open Document, RTF, Adobe PDF, HTML, Text Plain, Epub (но форматирование исчезает – нарушается компоновка картинок с текстом) |
| Размер файла | До 2 Мб |
| Ограничения | Ограничено только размером хранилищ Google. Качество исходника рекоменовано не меньше 10 пикселей по высоте для строки. |
| Качество | Так себе – качество распознавания свидетельства инн хуже, чем с Finereader. И ФИО, и номер инн полностью потеряны. |
Как пользоваться
У вас должен быть Google-аккаунт для пользования сервисом, если есть почта gmail – подойдет аккаунт от нее.
- Загрузите файл на страницу drive.google.com или выберите там уже загруженную картинку
- Нажмите правой кнопкой мыши на нужный файл.
- Выберите “Открыть с помощью” –> “Google Документы”.

- Картинка преобразуется в документ Google и откроется на вкладке https://docs.google.com

Abbyy Finereader
В Abbyy Finereader Online самый удобный интерфейс, хорошее качество, но доступна только ознакомительная версия – можно распознать не более 10 страниц за две недели. (200 страниц в месяц стоят 299р). Для использования сервиса нужно зарегистрироваться (можно войти через аккаунты социальных сетей). Кроме того, полученный текст можно там же перевести на другой язык с помощью машинного перевода.
Бесплатно доступно не более 10 страниц в две недели.
| Входные форматы | PDF, TIF, JPEG, BMP, PCX, PNG |
| Выходные форматы | Word, Excel, Power Point, Open Document, RTF, Adobe PDF, Text Plain, Fb2, Epub |
| Размер файла | До 100Мб |
| Ограничения | 10 картинок на две недели |
| Качество | Качество распознавания свидетельства инн оказалось хорошее. Примерно как у Online OCR – какие-то части документа лучше распознались тем сервисом, а какие-то – этим. |
 Результат распознавания Finereader. (ФИО и город распознаны, но стерты вручную)
Результат распознавания Finereader. (ФИО и город распознаны, но стерты вручную)Как пользоваться
- Загрузите файлы
- Выберите язык

- Выберите выходной формат
- Щелкните кнопку «Распознать»

Распознавание текста онлайн без регистрации
Online OCR
Online OCR http://www.onlineocr.net/ – единственный наряду с Abbyy Finereader сервис, который позволяет сохранять в выходном формате картинки вместе с текстом. Вот как выглядит распознанный вариант с выходным форматом Word:
 Результат распознавания в Online OCR (ФИО и дата распознаны, но стерты вручную)
Результат распознавания в Online OCR (ФИО и дата распознаны, но стерты вручную)| Входные форматы | PDF, TIF, JPEG, BMP, PCX, PNG, GIF |
| Выходные форматы | Word, Excel, Adobe PDF, Text Plain |
| Размер файла | До 5Мб без регистрации и до 100Мб с ней |
| Ограничения | Распознает не более 15 картинок в час без регистрации |
| Качество | Качество распознавания свидетельства инн оказалось хорошее. Примерно как у Abbyy Finereader – какие-то части документа лучше распознались тем сервисом, а какие-то – этим. |
Как пользоваться
- Загрузите файл (щелкните «Select File»)
- Выберите язык и выходной формат
- Введите капчу и щелкните «Convert»

Внизу появится ссылка на выходной файл (текст с картинками) и окно с текстовым содержимым
Free Online OCR
Free Online OCR https://www.newocr.com/ позволяет выделить часть изображения. Выдает результат в текстовом формате (картинки не сохраняются).
| Входные форматы | PDF, DjVu JPEG, PNG, GIF, BMP, TIFF |
| Выходные форматы | Text Plain (PDF и Word тоже можно загрузить, но внутри них все равно текст без форматирования и картинок). |
| Размер файла | До 5Мб без регистрации и до 100Мб с ней |
| Ограничения | Ограничения на количество нет |
| Качество | Качество распознавания свидетельства инн плохое. |
Можно распознавать как все целиком, так и выделить часть изображения для распознавания.
Как пользоваться
- Выберите файл или вставьте url файла и щелкните «Preview» – картинка загрузится и появится в окне браузера
 Не забудьте правильно указать язык.
Не забудьте правильно указать язык. - Выберите область сканирования (можно оставить целиком как есть)

- Выберите языки, на которых написан текст на картинке и щелкните кнопку «OCR»

- Внизу появится окно с текстом
OCR Convert
OCR Convert http://www.ocrconvert.com/ txt
| Входные форматы | Многостраничные PDF, JPG, PNG, BMP, GIF, TIFF |
| Выходные форматы | Text Plain |
| Размер файла | До 5Мб общий размер файлов за один раз. |
| Ограничения | Одновременно до 5 файлов. Сколько угодно раз. |
| Качество | Качество распознавания свидетельства инн среднее. (ФИО распознано частично). Лучше, чем Google, хуже, чем Finereader |
Как пользоваться
-
-
- Загрузите файл, выберите язык и щелкните кнопку «Process»
-

-
-
- Появится ссылка на файл с распознанным текстом
-

Free OCR
Free OCR www.free-ocr.com распознал документ хуже всех.
| Входные форматы | PDF, JPG, PNG, BMP, GIF, TIFF |
| Выходные форматы | Text Plain |
| Размер файла | До 6Мб |
| Ограничения | У PDF-файла распознается только первая страница |
| Качество | Качество распознавания свидетельства инн низкое – правильно распознано только три слова. |
Как пользоваться
-
-
- Выберите файл
- Выберите языки на картинке
- Щелкните кнопку “Start”
-
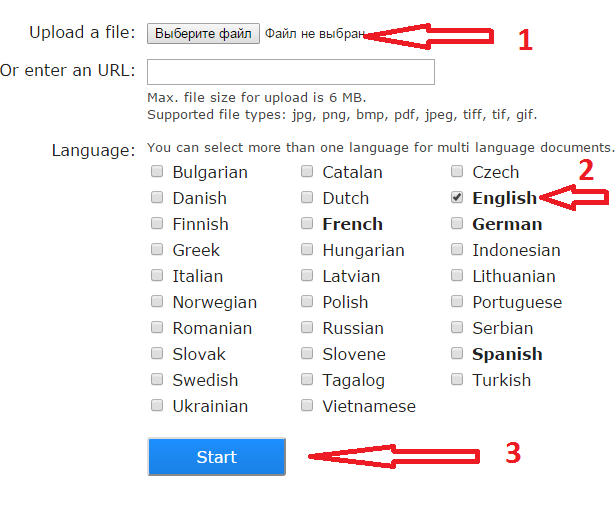
I2OCR
I2OCR http://www.i2ocr.com/ неплохой сервис со средним качеством выходного файла. Отличается приятным дизайном, отсутствием ограничений на количество распознаваемых картинок. Но временами зависает.
| Входные форматы | JPG, PNG, BMP, TIF, PBM, PGM, PPM |
| Выходные форматы | Text Plain (PDF и Word тоже можно загрузить, но внутри них все равно текст без форматирования и картинок). |
| Размер файла | До 10Мб |
| Ограничения | нет |
| Качество | Качество распознавания свидетельства инн среднее – сравнимо с OCR Convert. Замечено, что сервис временами не работает. |
Как пользоваться
- Выберите язык
- Загрузите файл
- Введите капчу
- Щелкните кнопку «Extract text»
- По кнопке «Download» можно загрузить выходной файл в нужном формате
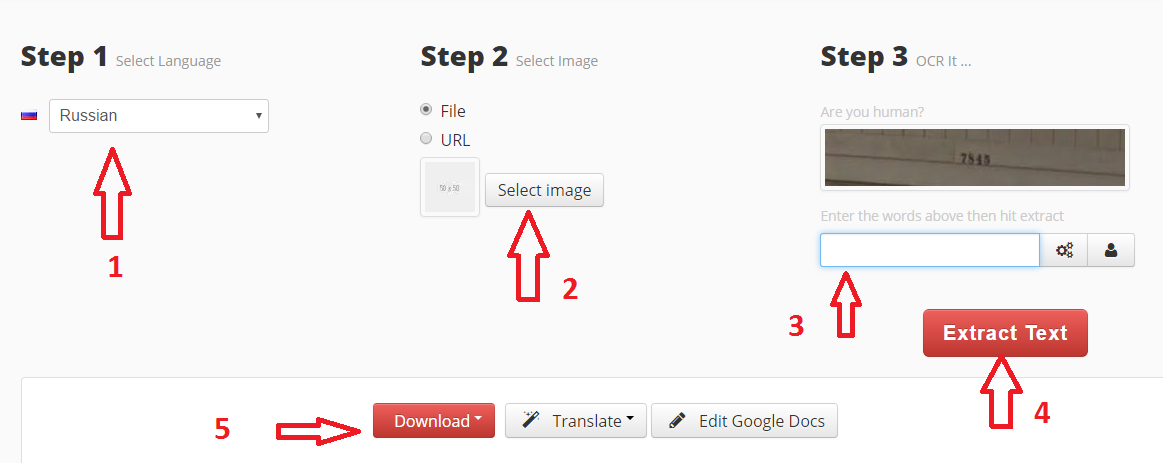
Яндекс OCR
Недавно обнаружила этот сервис, и он мне очень понравился качеством и простотой использования. Вообще то он предназначен для перевода загруженной картинки, но его можно использоваться и для распознавания текста с картинки. Регистрации не требует, ограничений на количество изображений нет. В данный момент находится в стадии бета-тестирования.
Просто перейдите на https://translate.yandex.ru/ocr, загрузите картинку (можно перетащить) и щелкните “Открыть в Переводчике”. Откроется как текст с картинки, так и перевод в правом поле.
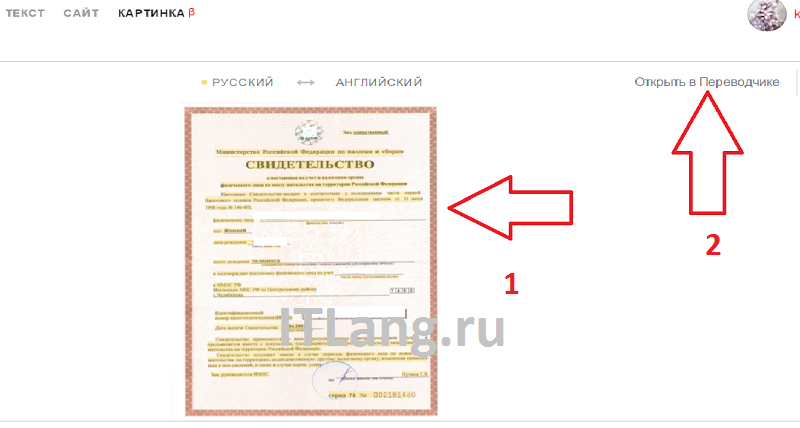 Перетащите картинку
Перетащите картинку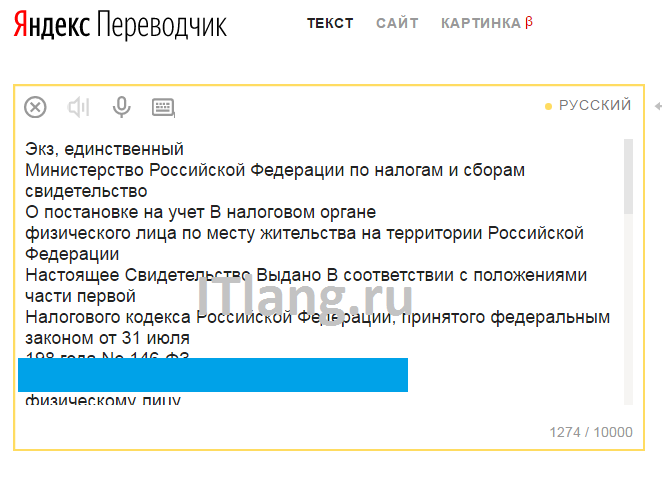 Результат распознавания
Результат распознаванияConvertio
Convertio hhttps://convertio.co/ru/ocr/ работает своеобразно, поэтому сравнивать его тяжело. В целом не понравился. Свидетельство ИНН, загруженное целиком, он не распознал совсем, так как плохо выделяет текст среди картинок. Не распозналось ни одного слова! Для его проверки я вырезала текстовый кусочек из ИНН и распознала его – это удалось сделать.
К тому же временами он зависает в попытках что-либо распознать.
| Входные форматы | pdf, jpg, bmp, gif, jp2, jpeg, pbm, pcx, pgm, png, ppm, tga, tiff, wbmp, webp |
| Выходные форматы | Text Plain, PDF, Word , Excel, Pptx, Djvu, Epub, Fb2, Csv |
| Размер файла | ?, зависит от тарифа |
| Ограничения | 10 страниц бесплатно, дальше тарифы от 7 долларов. |
| Качество | Сложно оценить – файл с картинками (ИНН) не распознал совсем, отдельно вырезанный кусок текста распознал. Замечено, что при распознавании сервис временами зависает, возможно ваши картинки ставятся в большую очередь на бесплатном тарифе. |
Как пользоваться
- Загрузите файл
- Выберите язык
- Выберите выходной формат
- Введите капчу
- Щелкните “Преобразовать”
- Чтобы увидеть результат, промотайте наверх к форме загрузки файлов. Там же можно будет и скачать результат.
 Интерфейс Convertio
Интерфейс ConvertioВырезанный и распознанный кусок (целиком не распознается):
 Результат работы Convertio
Результат работы ConvertioЗаключение
Лучше всего документ распознал Abbyy Finereader и Online OCR. Кроме того, эти сервисы сохраняют форматирование файла: где нет текста, оставляют картинки и компонуют их с распознанным текстом. Из новых сервисов хорош Яндекс OCR.
Хуже всего сработал Free OCR – он распознал всего три слова.
itlang.ru
Чтобы распознавать картинки, не нужно распознавать картинки / Хабр
Посмотрите на это фото.
Это совершенно обычная фотография, найденная в Гугле по запросу «железная дорога». И сама дорога тоже ничем особенным не отличается.
Что будет, если убрать это фото и попросить вас нарисовать железную дорогу по памяти?
Если вы ребенок лет семи, и никогда раньше не учились рисовать, то очень может быть, что у вас получится что-то такое: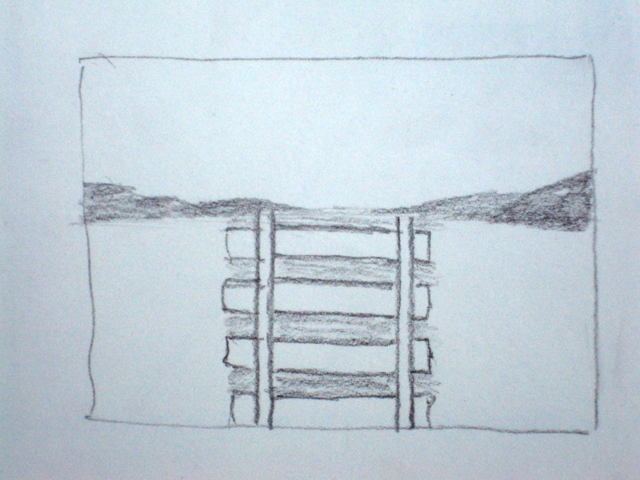 Упс. Кажется, что-то пошло не так.
Упс. Кажется, что-то пошло не так.
На самом деле, если долго разглядывать ее, становится понятно, что она не совсем точно отображает окружающий мир. Главная проблема, о которую мы немедленно споткнулись — там, например, пересекаются параллельные прямые. Ряд одинаковых (в реальности) фонарных столбов на самом деле изображен так, что каждый следующий столб имеет все меньшие и меньшие размеры. Деревья вокруг дороги, у которых поначалу различимы отдельные ветки и листья, сливаются в однотонный фон, который еще и вдобавок почему-то приобретает отчетливо-фиолетовый оттенок. Все это — эффекты перспективы, последствия того, что трехмерные объекты снаружи проецируются на двумерную сетчатку внутри глаза. Ничего отдельно магического в этом нет — разве что немного любопытно, почему эти искажения контуров и линий не вызывают у нас никаких проблем при ориентации в пространстве, но вдруг заставляют мозг напрячься при попытке взяться за карандаш.
Еще один замечательный пример — как маленькие дети рисуют небо.
 Небо должно быть наверху — вот она, синяя полоска, пришпиленная к верхнему краю. Середина листа при этом остается белой, заполнена пустотой, в которой плавает солнце.
Небо должно быть наверху — вот она, синяя полоска, пришпиленная к верхнему краю. Середина листа при этом остается белой, заполнена пустотой, в которой плавает солнце.
И так происходит всегда и везде. Мы знаем, что куб состоит из квадратных граней, но посмотрите на картинку, и вы не увидите там ни одного прямого угла — более того, эти углы постоянно меняются, стоит сменить угол обзора. Как будто где-то в голове у нас сохранена грубая схема правильного, трехмерного объекта, и именно к ней мы обращаемся в процессе рисования рельс, не сразу успевая сопоставить результат с тем, что видим своими глазами.
На самом деле все еще хуже. Каким образом, например, на самой первой картинке с дорогой мы определяем, какая часть дороги расположена ближе к нам, а какая дальше? По мере удаления предметы становятся меньше, ок — но вы уверены, что кто-то не обманул вас, коварно разместив друг за другом последовательно уменьшающиеся шпалы? Далекие объекты обычно имеют бледно-голубоватый оттенок (эффект, который называется «атмосферная перспектива») — но предмет может быть просто окрашен в такой цвет, и в остальном казаться совершенно нормальным. Мост через железнодорожные пути, который едва видно отсюда, кажется нам находящимся позади, потому что его заслоняют фонари (эффект окклюзии) — но опять-таки, как вы можете быть уверены, что фонари просто не нарисованы на его поверхности? Весь этот набор правил, с помощью которых вы оцениваете трехмерность сцены, во многом зависит от вашего опыта, и возможно, генетического опыта ваших предков, обученных выживать в условиях нашей атмосферы, падающего сверху света и ровной линии горизонта.
Сама по себе, без помощи мощной аналитической программы в вашей голове, наполненной этим визуальным опытом, любая фотография говорит об окружающем мире ужасно мало. Изображения — это скорее такие триггеры, заставляющие вас мысленно представить себе сцену, большая часть знаний о которой уже есть у вас в памяти. Они не содержат реальных предметов — только ограниченные, сплющенные, трагически двумерные представления о них, которые, к тому же, постоянно меняются при движении. В чем-то мы с вами — такие же жители Флатландии, которые могут увидеть мир только с одной стороны и неизбежно искаженным.
больше перспективыВообще мир вокруг прямо-таки полон свидетельств того, как перспектива все искажает. Люди, поддерживающие пизанскую башню, фотографии с солнцем в руках, не говоря уже про классические картины Эшера, или вот совершенно прекрасный пример — Комната Эймса. Тут важно понять, что это не какие-то единичные подлянки, специально сделаные для того, чтобы обманывать. Перспектива всегда показывает нам неполноценную картинку, просто как правило, мы способны ее «раскодировать». Попробуйте выглянуть в окно и подумать, что то, что вы видите — обман, искажение, безнадежная неполноценность. Представьте, что вы — нейронная сеть.Это не должно быть очень сложно — в конце концов, как-то так оно и есть на самом деле. Вы проводите свободное время за распознаванием лиц на документах в паспортном столе. Вы — очень хорошая нейронная сеть, и работа у вас не слишком сложная, потому что в процессе вы ориентируетесь на паттерн, строго характерный именно для человеческих лиц — взаимное расположение двух глаз, носа и рта. Глаза и носы сами по себе могут различаться, какой-то один из признаков иногда может оказаться на фотографии неразличимым, но вам всегда помогает наличие других. И вдруг вы натыкаетесь вот на такое:
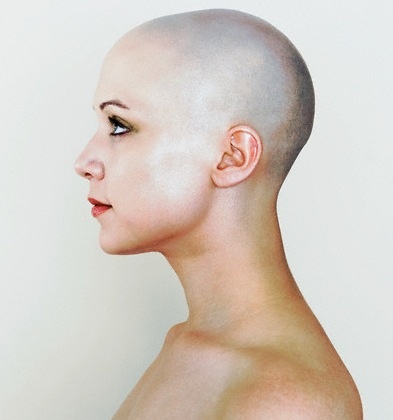
Хм, думаете вы. Вы определенно видите что-то знакомое — по крайней мере, в центре, кажется, есть один глаз. Правда, странной формы — он похож на треугольник, а не на заостренный овал. Второго глаза не видно. Нос, который должен располагаться посередине и между глаз, уехал куда-то совсем в край контура, а рта вы вообще не нашли — опредленно, темный уголок снизу-слева совсем на него не похож. Не лицо — решаете вы, и выбрасываете картинку в мусорное ведро.
Так бы мы думали, если бы наша зрительная система занималась простым сопоставлением паттернов в изображениях. К счастью, думает она как-то по-другому. У нас не вызывает никакого беспокойства отсутствие второго глаза, от этого лицо не становится менее похожим на лицо. Мы мысленно прикидываем, что второй глаз должен находиться по ту сторону, и форма его обусловлена исключительно тем, что голова на фото повернута и смотрит в сторону. Кажется невозможно тривиальным, когда пытаешься это объяснить на словах, но кое-кто с вами бы на полном серьезе не согласился.
Самое обидное, что не видно, как можно решить этот вопрос механическим способом. Компьютерное зрение сталкивалось с соответствующими проблемами очень давно, с момента своего появления, и периодически находило эффективные частные решения — так, мы можем опознать сдвинутый в сторону предмет, последовательно передвигая свой проверочный паттерн по всему изображению (чем успешно пользуются сверточные сети), можем справляться с отмасштабированными или повернутыми картинками с помощью признаков SIFT, SURF и ORB, но эффекты перспективы и поворот предмета в пространстве сцены — похоже, вещи качественно другого уровня. Здесь нам нужно знать, как предмет выглядит со всех сторон, получить его истинную трехмерную форму, иначе нам не с чем работать. Поэтому чтобы распознавать картинки, не нужно распознавать картинки. Они лживы, обманчивы и заведомо неполноценны. Они — не наши друзья.
Итак, важный вопрос — как бы нам получать трехмерную модель всего, что мы видим? Еще более важный вопрос — как при этом обойтись без необходимости покупать лазерный пространственный сканер (сначала я написал «чертовски дорогой лазерный сканер», а потом наткнулся на этот пост)? Даже не столько по той причине, что нам жалко, а потому, что животные в процессе эволюции зрительной системы явно каким-то образом обошлись без него, одними только глазами, и было бы любопытно выяснить, как они так.Где-то в этом месте часть аудитории обычно встает и выходит из зала, ругаясь на топтание по матчасти — все знают, что для восприятия глубины и пространства мы пользуемся бинокулярным зрением, у нас для этого два специальных глаза! Если вы тоже так думаете, у меня для вас небольшой сюрприз — это неправда. Доказательство прекрасно в своей простоте — достаточно закрыть один глаз и пройтись по комнате, чтобы убедиться, что мир внезапно не утратил глубины и не стал походить на плоский аналог анимационного мультфильма. Еще один способ — вернуться и снова посмотреть на фотографию с железной дорогой, где замечательно видно глубину даже при том, что она расположена на полностью плоской поверхности монитора.
Вообще с двумя глазами все не так простоДля некоторых действий они, похоже, и правда приносят пользу с точки зрения оценки пространственного положения. Возьмите два карандаша, закройте один глаз и попытайтесь сдвигать эти карандаши так, чтобы они соприкоснулись кончиками грифелей где-то вблизи вашего лица. Скорее всего, грифели разойдутся, причем ощутимо (если у вас получилось легко, поднесите их еще ближе к лицу), при этом со вторым открытым глазом такого не происходит. Пример взят из книги Марка Чангизи «Революция в зрении» — там есть целая глава о стереопсисе и бинокулярном зрении с любопытной теорией о том, что два смотрящих вперед глаза нужны нам для того, чтобы видеть сквозь мелкие помехи вроде свисающих листьев. Кстати, забавный факт — на первом месте в списке преимуществ бинокулярного зрения в Википедии стоит «It gives a creature a spare eye in case one is damaged».
Итак, бинокулярное зрение нам не подходит — и вместе с ним мы отвергаем стереокамеры, дальномеры и Kinect. Какой бы ни была способость нашей зрительной системы воссоздавать трехмерные образы увиденного, она явно не требует наличия двух глаз. Что остается в итоге?
Я ни в коем случае не готов дать точный ответ применительно к биологическом зрению, но пожалуй, для случая абстрактного робота с камерой вместо глаза остался один многообещающий способ. И этот способ — движение.
Вернемся к теме поездов, только на этот раз выглянем из окна:

То, что мы при этом видим, называется «параллакс движения», и вкратце он заключается в том, что когда мы двигаемся вбок, близкие предметы смещаются в поле зрения сильнее, чем далекие. Для движения вперед/назад и поворотов тоже можно сформулировать соответствующие правила, но давайте их пока проигнорируем. Итак, мы собираемся двигаться, оценивать смещения предметов в кадре и на основании этого определять их расстояние от наблюдателя — техника, которая официально называется «structure-from-motion». Давайте попробуем.
Прежде всего — а не сделали ли все, случайно, до нас? Страница «Structure from motion» в Википедии предлагает аж тринадцать инструментов (и это только опенсорсных) для воссоздания 3D-моделей из видео или набора фотографий, большинство из них пользуются подходом под названием bundle adjustment, а самым удобным мне показался Bundler (и демо-результаты у него крутые). К сожалению, тут возникает проблема, с которой мы еще столкнемся — Bundler для корректной работы хочет знать от нас модель камеры и ее внутренние параметры (в крайнем случае, если модель неизвестна, он требует указать фокусное расстояние).Если для вашей задачи это не проблема — можете смело бросать чтение, потому что это самый простой и одновременно эффективный метод (а знаете, кстати, что примерно таким способом делались модели в игре «Исчезнование Итана Картера»?). Для меня, увы, необходимость быть привязанным к модели камеры — это условие, которого очень хотелось бы избежать. Во-первых, потому что у нас под боком полный ютуб визуального видео-опыта, которым хотелось бы в будущем пользоваться в качестве выборки. Во-вторых (и это, может быть, даже важнее), потому что наш с вами человеческий мозг, похоже, если и знает в цифрах внутренние параметры камеры наших глаз, то прекрасно умеет приспосабливаться к любым оптическим искажениями. Взгляд через объектив широкофокусной камеры, фишай, просмотр кино и ношение окулусрифта совершенно не разрушает ваших зрительных способностей. Значит, наверное, возможен и какой-то другой путь.
Итак, мы печально закрыли страницу с Итаном Картером википедии и опускаемся на уровень ниже — в OpenCV, где нам предлагают следующее:
1. Взять два кадра, снятые с откалиброванной камеры. 2. Вместе с параметрами калибровки (матрицей камеры) положить их оба в функцию stereoRectify, которая выпрямит (ректифицирует) эти два кадра — это преобразование, которое искажает изображение так, чтобы точка и ее смещение оказывались на одной горизонтальной прямой. 3. Эти ректифицированые кадры мы кладем в функцию stereoBM и получаем карту смещений (disparity map) — такую картинку в оттенках серого, где чем пиксель ярче, тем большее смещение он выражает (по ссылке есть пример). 4. Полученную карту смещений кладем в функцию с говорящим названием reprojectImageTo3D (понадобится еще и матрица Q, которую в числе прочих мы получим на шаге 2). Получаем наш трехмерный результат.
Черт, похоже, мы наступаем на те же грабли — уже в пункте 1 от нас требуют откалиброванную камеру (правда, OpenCV милостиво дает возможность сделать это самому). Но погодите, здесь есть план Б. В документации прячется функция с подозрительным названием stereoRectifyUncalibrated…
План Б:
1. Нам нужно оценить примерную часть смещений самим — хотя бы для ограниченного набора точек. StereoBM здесь не подойдет, поэтому нам нужен какой-то другой способ. Логичным вариантом будет использовать feature matching — найти какие-то особые точки в обоих кадрах и выбрать сопоставления. Про то, как это делается, можно почитать здесь. 2. Когда у нас есть два набора соответствующих друг другу точек, мы можем закинуть их в findFundamentalMat, чтобы получить фундаментальную матрицу, которая понадобится нам для stereoRectifyUncalibrated. 3. Запускаем stereoRectifyUncalibrated, получаем две матрицы для ректификации обоих кадров. 4. И… а дальше непонятно. Выпрямленные кадры у нас есть, но нет матрицы Q, которая была нужна для завершающего шага. Погуглив, я наткнулся примерно на такой же недоумения пост, и понял, что либо я что-то упустил в теории, либо в OpenCV этот момент не продумали.
OpenCV: мы — 2:0.
4.1 Меняем план
Но погодите. Возможно, мы с самого начала пошли не совсем правильным путем. В предыдущих попытках мы, по сути, пытались определить реальное положение трехмерных точек — отсюда необходимость знать параметры камеры, матрицы, ректифицировать кадры и так далее. По сути, это обычная триангуляция: на первой камере я вижу эту точку здесь, а на второй здесь — тогда нарисуем два луча, проходящих через центры камер, и их пересечение покажет, как далеко точка от нас находится.Это все прекрасно, но вообще говоря, нам не нужно. Реальные размеры предметов интересовали бы нас, если бы наша модель использовалась потом для промышленных целей, в каких-нибудь 3d-принтерах. Но мы собираемся (эта цель слегка уже расплылась, правда) запихивать полученные данные в нейросети и им подобные классификаторы. Для этого нам достаточно знать только относительные размеры предметов. Они, как мы все еще помним, обратно пропорциональны смещениям параллакса — чем дальше от нас предмет, тем меньше смещается при нашем движении. Нельзя ли как-то найти эти смещения еще проще, просто каким-то образом сопоставив обе картинки?
Само собой, можно. Привет, оптический поток.
Это замечательный алгоритм, который делает ровно то, что нам нужно. Кладем в него картинку и набор точек. Потом кладем вторую картинку. Получаем на выходе для заданных точек их новое положение на второй картинке (приблизительное, само собой). Никаких калибровок и вообще никаких упоминаний о камере — оптический поток, несмотря на название, можно рассчитывать на базе чего угодно. Хотя обычно он все-таки используется для слежения за объектами, обнаружения столкновений и даже дополненной реальности.
Для наших целей мы (пока) хотим воспользоваться «плотным» потоком Гуннара Фарнебака, потому что он умеет рассчитывать поток не для каих-то отдельных точек, а для всей картинки сразу. Метод доступен с помощью calcOpticalFlowFarneback, и первые же результаты начинают очень-очень радовать — смотрите, насколько оно выглядит круче, чем предыдущий результат stereoRectifyUncalibrated + stereoBM.
 Большое спасибо замечательной игре Portal 2 за возможность строить собственные комнаты и играть в кубики. I'm doin' Science!
Большое спасибо замечательной игре Portal 2 за возможность строить собственные комнаты и играть в кубики. I'm doin' Science!
Итак, отлично. Смещения у нас есть, и на вид неплохие. Как теперь нам получить из них координаты трехмерных точек?
4.2 Часть, в которой мы получаем координаты трехмерных точек
Эта картинка уже мелькала на одной из ссылок выше.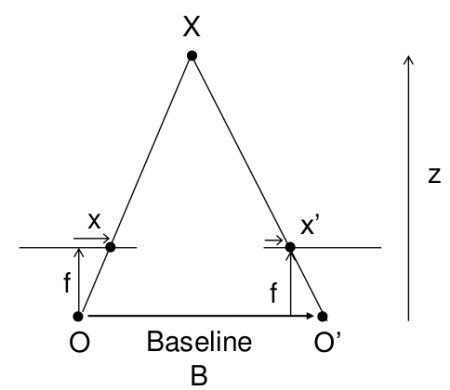
Расстояние до объекта здесь рассчитывается методом школьной геометрии (подобные треугольники), и выглядит так: 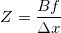 . А координаты, соответственно, вот так:
. А координаты, соответственно, вот так: 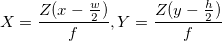 . Здесь w и h — ширина и высота картинки, они нам известны, f — фокусное расстояние камеры (расстояние от центра камеры до поверхности ее экрана), и B — камеры же шаг. Кстати, обратите внимание, что мы тут слегка нарушаем общепринятые названия осей, когда Z направлена вверх — у нас Z смотрит «вглубь» экрана, а X и Y — соответственно, направлены по ширине и высоте картинки.
. Здесь w и h — ширина и высота картинки, они нам известны, f — фокусное расстояние камеры (расстояние от центра камеры до поверхности ее экрана), и B — камеры же шаг. Кстати, обратите внимание, что мы тут слегка нарушаем общепринятые названия осей, когда Z направлена вверх — у нас Z смотрит «вглубь» экрана, а X и Y — соответственно, направлены по ширине и высоте картинки.
Ну, насчет f все просто — мы уже оговаривали, что реальные параметры камеры нас не интересуют, лишь бы пропорции всех предметов изменялись по одному закону. Если подставить Z в формулу для X выше, то можно увидеть, что X от фокусного расстояния вообще не зависит (f сокращается), поэтому разные его значения буду менять только глубину — «вытягивать» или «сплющивать» нашу сцену. Визуально — не очень приятно, но опять же, для алгоритма классификации — совершенно все равно. Так что зададим фокусное расстояние интеллектуальным образом — просто придумаем. Я, правда, оставляю за собой право слегка изменить мнение дальше по тексту.
Насчет B чуть посложнее — если у нас нет встроенного шагомера, мы не знаем, на какую дистанцию переместилась камера в реальном мире. Так что давайте пока немного считерим и решим, что движение камеры происходит примерно плавно, кадров у нас много (пара десятков на секунду), и расстояние между двумя соседними примерно одинаковое, т.е. 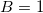 . И опять же, дальше мы слегка уточним эту ситуацию, но пока пусть будет так.
. И опять же, дальше мы слегка уточним эту ситуацию, но пока пусть будет так.
Вот так выглядит результат. Надеюсь, эта гифка успела загрузиться, пока вы дочитали до этого места.
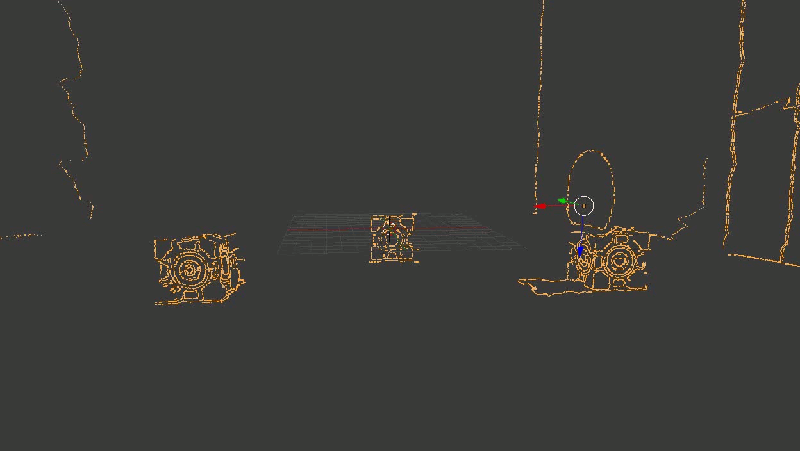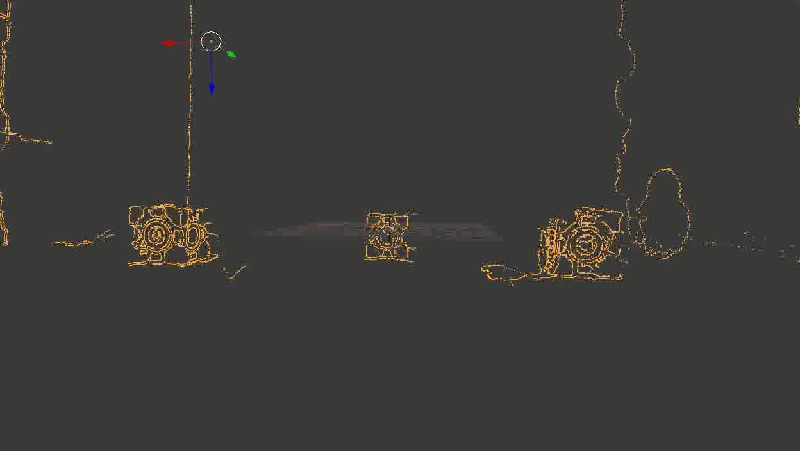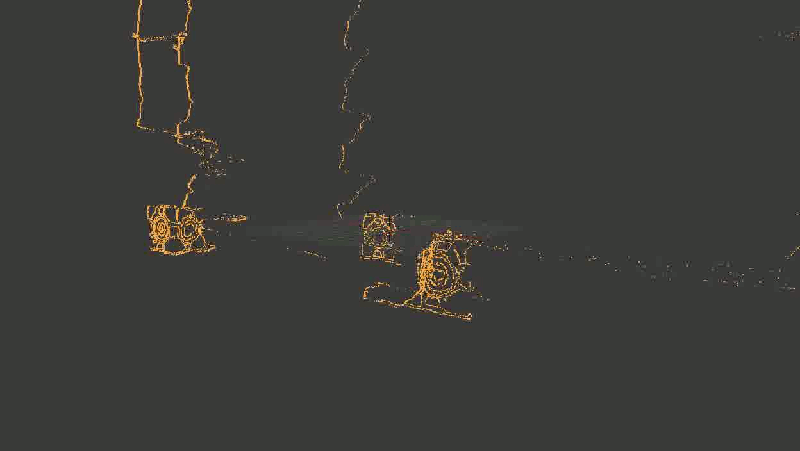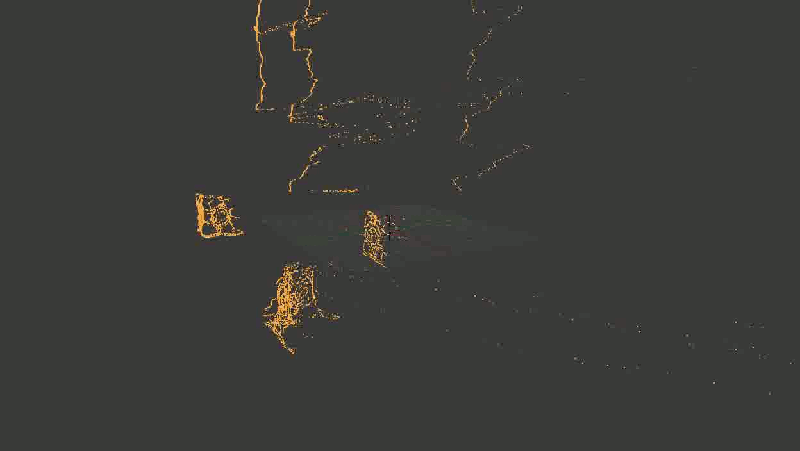 Для наглядности я взял не все точки подряд, а только границы, выделенные Canny-детектором
Для наглядности я взял не все точки подряд, а только границы, выделенные Canny-детектором
С первого взгляда (во всяком случае, мне) все показалось отличным — даже углы между гранями кубиков образовали симпатичные девяносто градусов. С предметами на заднем плане получилось похуже (обратите внимание, как исказились контуры стен и двери), но хэй, наверное, это просто небольшой шум, его можно будет вылечить использованием большего количества кадров или чем-нибудь еще.
Из всех возможных поспешных выводов, которые можно было здесь сделать, этот оказался дальше всех от истины.
В общем, основная проблема оказалась в том, что какая-то часть точек довольно сильно искажалась. И — тревожный знак, где уже пора было заподозрить неладное — искажалась не случайным образом, а примерно в одних и тех же местах, так что исправить проблему путем последовательного наложения новых точек (из других кадров) не получалось.Выглядело это примерно так: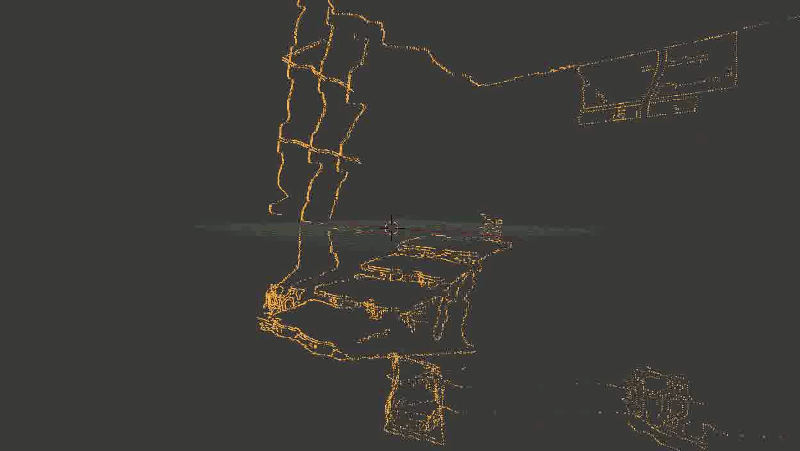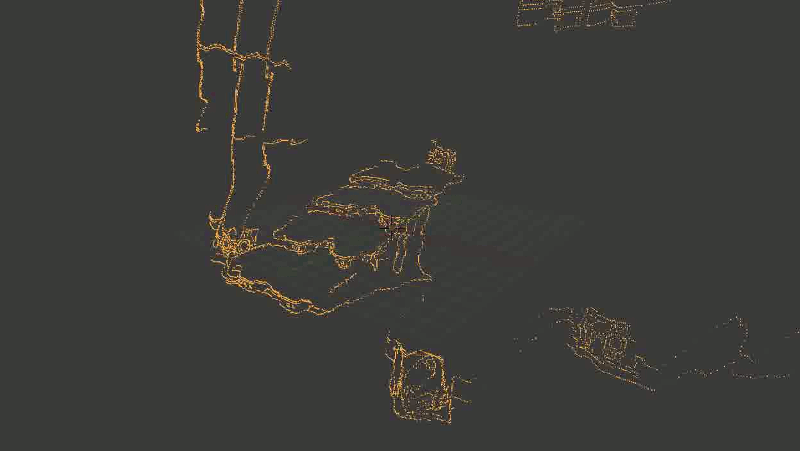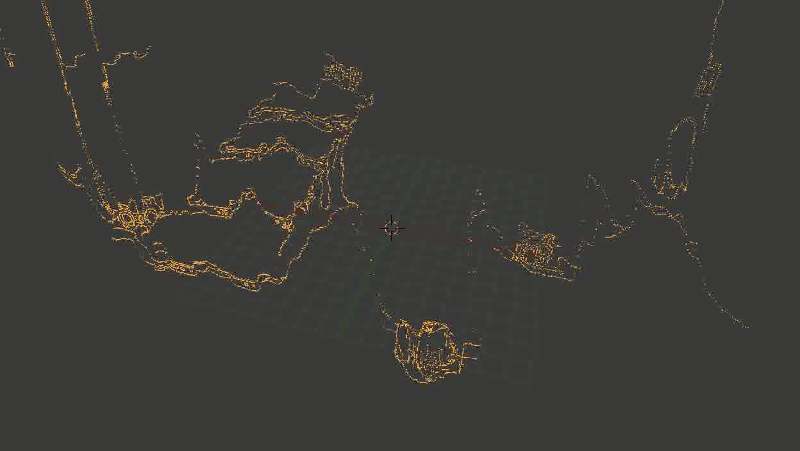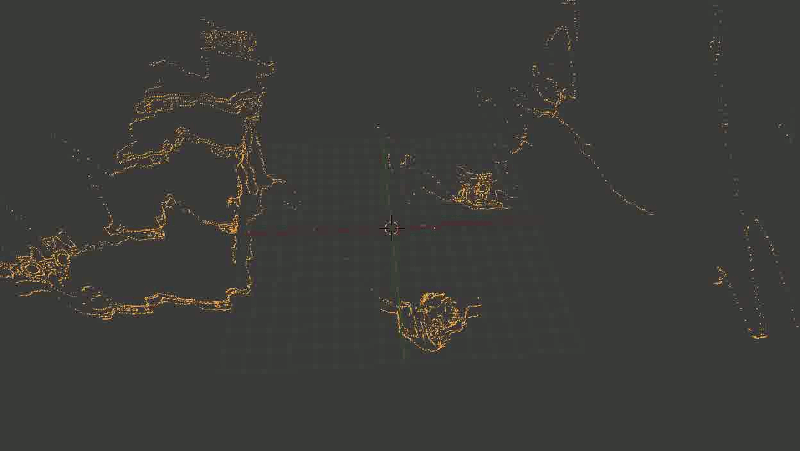 Лестница сминается, местами превращаясь в аморфный кусок непонятно-чего.
Лестница сминается, местами превращаясь в аморфный кусок непонятно-чего.Я очень долго пытался это починить, и за это время перепробовал следующее:
— сглаживать каринку с оптическим потоком: размытие по Гауссу, медианный фильтр и модный билатеральный фильтр, который оставляет четкими края. Бесполезно: предметы наоборот, еще сильнее расплывались.
— пытался находить на картинке прямые линии с помощью Hough transform и переносить их в неизменном прямом состоянии. Частично работало, но только на границах — поверхности по-прежнему оставались такими же искаженными; плюс никуда не получалось деть мысль в духе «а что если прямых линий на картинке вообще нет».
— я даже попытался сделать свою собственную версию оптического потока, пользуясь OpenCVшным templateMatching. Работало примерно так: для любой точки строим вокруг нее небольшой (примерно 10x10) квадрат, и начинаем двигать его вокруг и искать максимальное совпадение (если известно направление движения, то «вокруг» можно ограничить). Получилось местами неплохо (хотя работало оно явно медленнее оригинальной версии): Слева уже знакомый поток Фарнебака, справа вышеописаный велосипед
Слева уже знакомый поток Фарнебака, справа вышеописаный велосипед
С точки зрения шума, увы, оказалось ничуть не лучше.
В общем, все было плохо, но очень логично. Потому что так оно и должно было быть.
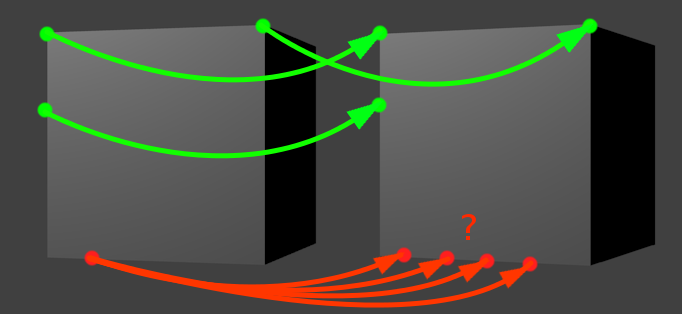 Иллюстрация к проблеме. Движение здесь — по-прежнему шаг вправо
Иллюстрация к проблеме. Движение здесь — по-прежнему шаг вправо
Давайте выберем какую-нибудь зеленую точку из картинки выше. Предположим, мы знаем направление движения, и собираемся искать «смещенного близнеца» нашей зеленой точки, двигаясь в заданном направлении. Когда мы решаем, что нашли искомого близнеца? Когда наткнемся на какой-нибудь «ориентир», характерный участок, который похож на окружение нашей начальной точки. Например, на угол. Углы в этом отношении легко отслеживать, потому что они сами по себе встречаются довольно редко. Поэтому если наша зеленая точка представляет собой угол, и мы находим похожий угол в заданной окрестности, то задача решена.
Чуть сложнее, но все еще легко обстоит ситуация с вертикальной линией (вторая левая зеленая точка). Учитывая, что мы двигаемся вправо, вертикальная линия встретится нам только один раз за весь период поиска. Представьте, что мы ползем своим поисковым окном по картинке и видим однотонный фон, фон, снова фон, вертикальный отрезок, опять фон, фон, и снова фон. Тоже несложно.
Проблема появляется, когда мы пытаемся отслеживать кусок линии, расположенной параллельно движению. У красной точки нет одного четко выраженного кандидата на роль смещенного близнеца. Их много, все они находятся рядом, и выбрать какого-то одного тем методом, что мы пользуемся, просто невозможно. Это функциональное ограничение оптического потока. Как нас любезно предупреждает википедия в соответствующей статье, «We cannot solve this one equation with two unknown variables», и тут уже ничего не сделаешь.
Совсем-совсем ничего?Вообще, если честно, то это, наверное, не совсем правда. Вы ведь можете найти на правой картинке соответствие красной точке? Это тоже не очень сложно, но для этого мы мысленно пользуемся каким-то другим методом — находим рядом ближайшую «зеленую точку» (нижний угол), оцениваем расстояние до нее и откладываем соответствующее расстояние на второй грани куба. Алгоритмам оптического потока есть куда расти — этот способ можно было бы и взять на вооружение (если этого еще не успели сделать).
На самом деле, как подсказывает к этому моменту запоздавший здравый смысл, мы все еще пытаемся сделать лишнюю работу, которая не важна для нашей конечной цели — распознавания, классификации и прочего интеллекта. Зачем мы пытаемся запихать в трехмерный мир все точки картинки? Даже когда мы работаем с двумерными изображениями, мы обычно не пытаемся использовать для классификации каждый пиксель — большая их часть не несет никакой полезной информации. Почему бы не делать то же самое и здесь?Собственно, все оказалось вот так просто. Мы будем рассчитывать тот же самый оптический поток, но только для «зеленых», устойчивых точек. И кстати, в OpenCV о нас уже позаботились. Нужная нам штука называется поток Лукаса-Канаде.
Приводить код и примеры для тех же самых случаев будет слегка скучно, потому что получится то же самое, но с гораздо меньшим числом точек. Давайте по дороге сделаем еще чего-нибудь: например, добавим нашему алгоритму возможность обрабатывать повороты камеры. До этого мы двигались исключительно вбок, что в реальном мире за пределами окон поездов встречается довольно редко.
С появлением поворотов координаты X и Z у нас смешиваются. Оставим старые формулы для расчета координат относительно камеры, и будем переводить их в абсолютные координаты следующим образом (здесь 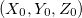 — координаты положения камеры, альфа — угол поворота):
— координаты положения камеры, альфа — угол поворота):
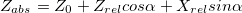
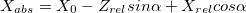
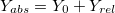
(игрек — читер; это потому, что мы считаем, что камера не двигается вверх-вниз)
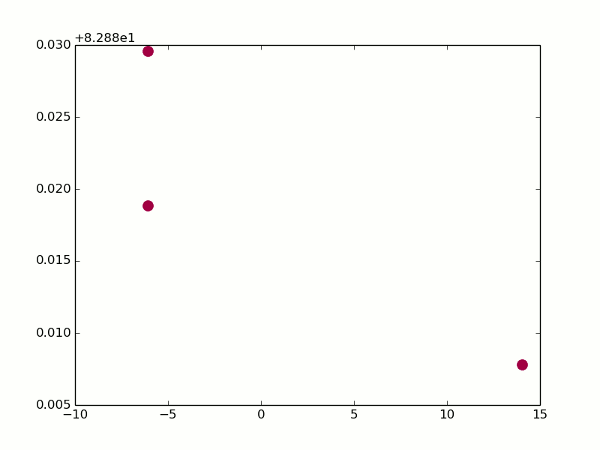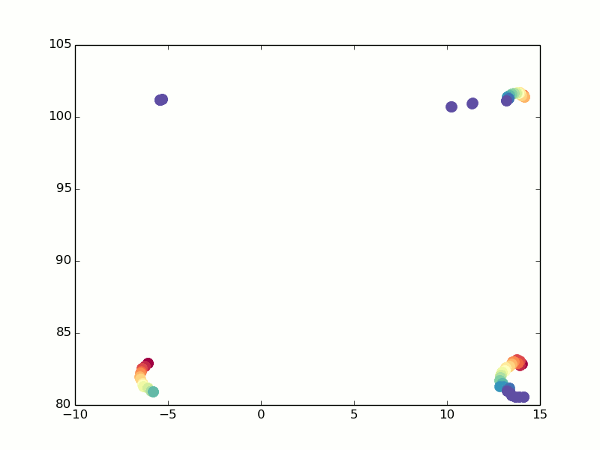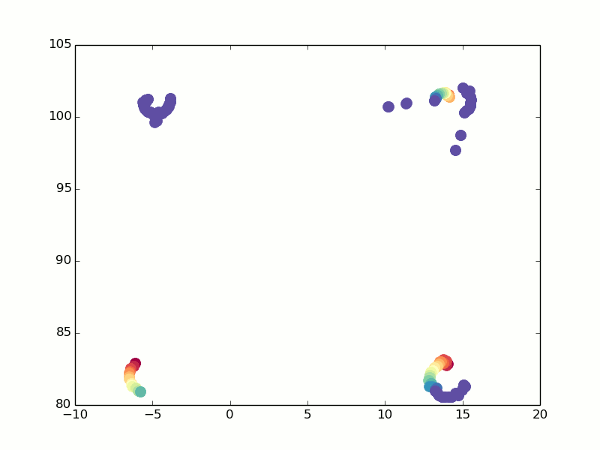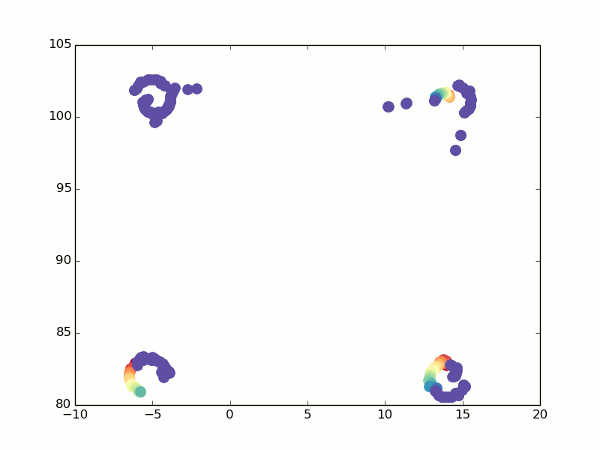
Где-то здесь же у нас появляются проблемы с фокусным расстоянием — помните, мы решили задать его произвольным? Так вот, теперь, когда у нас появилась возможность оценивать одну и ту же точку с разных углов, он начал иметь значение — именно за счет того, что координаты X и Z начали мешаться друг с другом. На самом деле, если мы запустим код, аналогичный предыдущему, с произвольным фокусом, мы увидим примерно вот что:
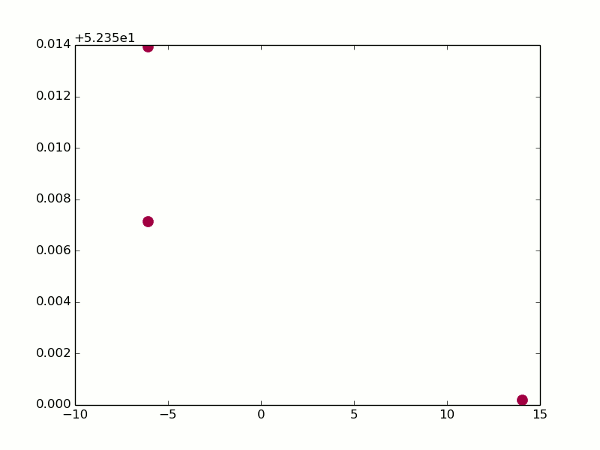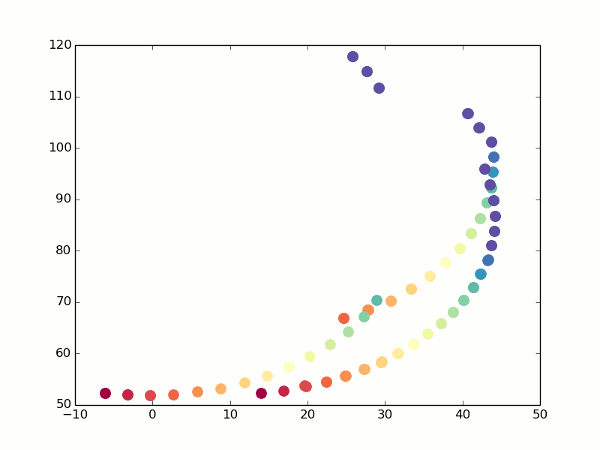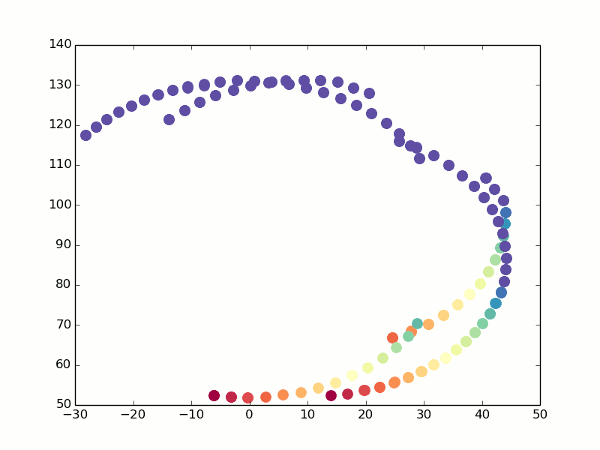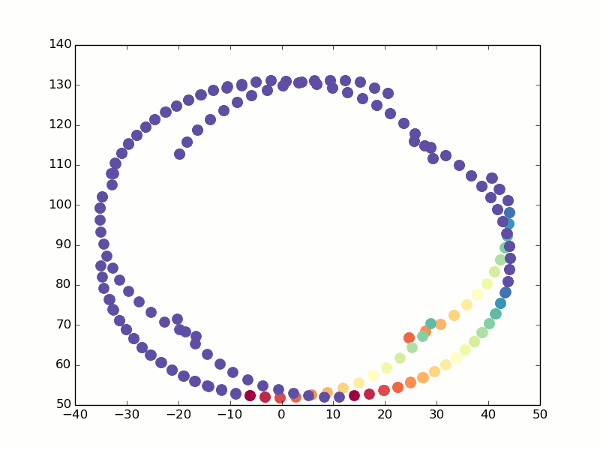 Неочевидно, но это попытка устроить обход камеры вокруг обычного кубика. Каждый кадр — оценка видимых точек после очередного поворота камеры. Вид сверху, как на миникарте.
Неочевидно, но это попытка устроить обход камеры вокруг обычного кубика. Каждый кадр — оценка видимых точек после очередного поворота камеры. Вид сверху, как на миникарте.
К счастью, у нас все еще есть оптический поток. При повороте мы можем увидеть, какие точки переходят в какие, и рассчитать для них координаты с двух углов зрения. Отсюда несложно получить фокусное расстояние (просто возьмите две вышеприведенных формулы для разных значений альфа, приравняйте координаты и выразите f). Так гораздо лучше:
 Не то что бы все точки легли идеально одна в другую, но можно хотя бы догадаться о том, что это кубик.
Не то что бы все точки легли идеально одна в другую, но можно хотя бы догадаться о том, что это кубик.
И, наконец, нам нужно как-то справляться с шумом, благодаря которому наши оценки положения точек не всегда совпадают (видите на гифке сверху аккуратные неровные колечки? вместо каждого из них, в идеале, должна быть одна точка). Тут уже простор для творчества, но наиболее адекватный способ мне показался таким: — когда у нас есть подряд несколько сдвигов в сторону, объединяем информацию с них вместе — так для одной точки у нас будет сразу несколько оценок глубины; — когда камера поворачивается, мы пытаемся совместить два набора точек (до поворота и после) и подогнать один к другому. Эта подгонка по-правильному называется «регистрацией точек» (о чем вы бы никогда не догадались, услышав термин в отрыве от контекста), и для нее я воспользовался алгоритмом Iterative closest point, нагуглив версию для питона + OpenCV; — потом точки, которые лежат в пределах порогового радиуса (определяем методом ближайшего соседа), сливаются вместе. Для каждой точки мы еще отслеживаем что-то типа «интенсивности» — счетчик того, как часто она объединялась с другими точками. Чем больше интенсивность — тем больше шанс на то, что это честная и правильная точка.
Результат может и не такой цельный, как в случае с кубиками из Портала, но по крайней мере, точный. Вот пара воссозданных моделей, которые я сначала загрузил в Блендер, покрутил вокруг них камеру и сохранил полученные кадры:
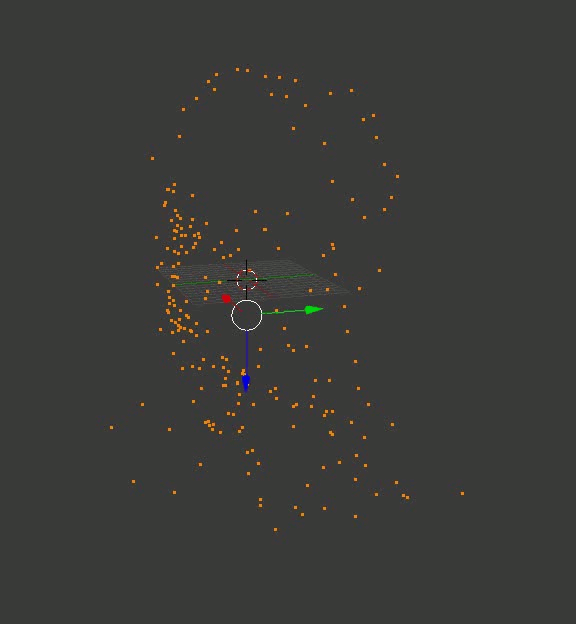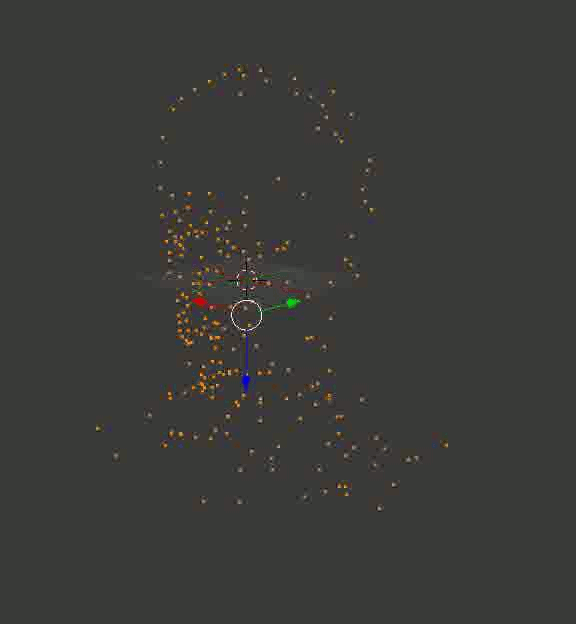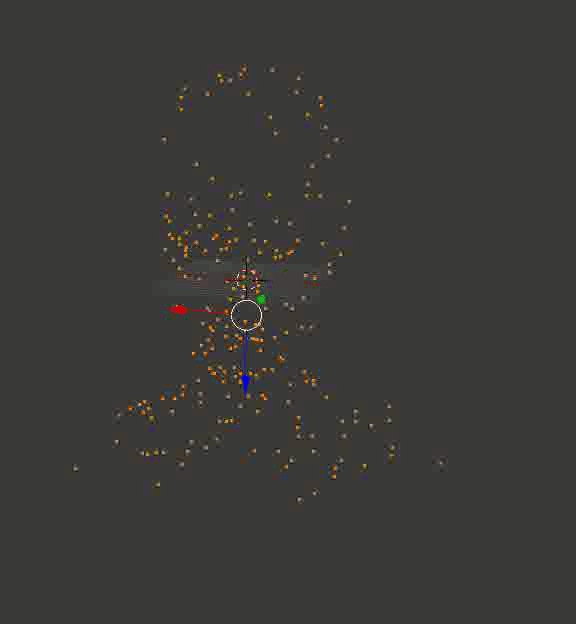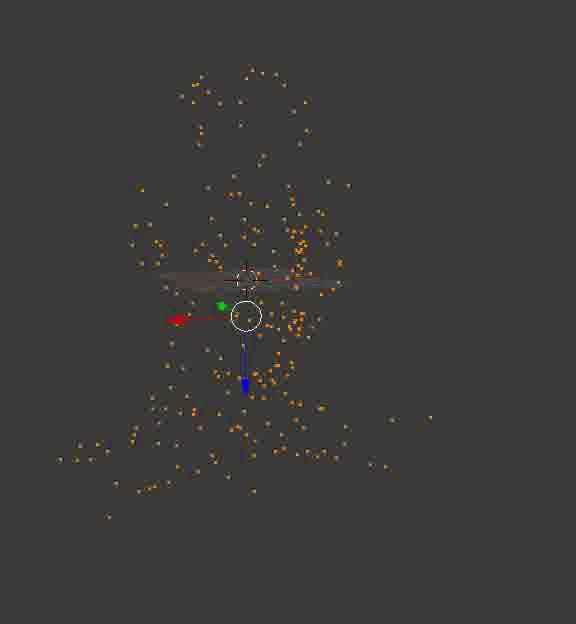 Голова профессора Доуэля
Голова профессора Доуэля
 Какая-то рандомная машина
Какая-то рандомная машина
Бинго! Дальше нужно их все запихать в распознающий алгоритм и посмотреть, что получится. Но это, пожалуй, оставим на следующую серию.
Слегка оглянемся назад и вспомним, зачем мы это все делали. Ход рассуждений был такой: — нам нужно уметь распознавать вещи, изображенные на картинках — но эти картинки каждый раз, когда мы меняем положение или смотрим на одну и ту же вещь с разных углов, меняются. Иногда до неузнаваемости — это не баг, а фича: следствие того, что наши ограниченые сенсоры глаз видят только часть предмета, а не весь предмет целиком — следовательно, нужно как-то объединить эти частичные данные от сенсоров и собрать из них представление о предмете в его полноценной форме.Вообще говоря, это ведь наверняка проблема не только зрения. Это скорее правило, а не исключение — наши сенсоры не всемогущи, они постоянно воспринимают информацию об объекте частями — но любопытно, насколько все подобные случаи можно объединить в какой-то общий фреймворк? Скажем (возвращаясь к зрению), ваши глаза сейчас постоянно совершают мелкие и очень быстрые движения — саккады — перескакивая между предметами в поле зрения (а в промежутках между этими движениями ваше зрение вообще не работает — именно поэтому нельзя увидеть собственные саккады, даже уставившись в зеркало в упор). Мозг постоянно занимается упорной работой по «сшиванию» увиденных кусочков. Это — та же самая задача, которую мы только что пытались решить, или все-таки другая? Восприятие речи, когда мы можем соотнести десяток разных вариантов произношения слова с одним его «идеальным» написанием — это тоже похожая задача? А как насчет сведения синонимов к одному «образу» предмета?
Если да — то возможно, проблема несколько больше, чем просто местечковый алгоритм зрительной системы, заменяющий нашим недоэволюционировавшим глазам лазерную указку сканера.
Очевидные соображения говорят, что когда мы пытаемся воссоздать какую-то штуку, увиденную в природе, нет смысла слепо копировать все ее составные части. Чтобы летать по воздуху, не нужны машущие крылья и перья, достаточно жесткого крыла и подъемной силы; чтобы быстро бегать, не нужны механические ноги — колесо справится гораздо лучше. Вместо того, чтобы копировать увиденное, мы хотим найти принцип и повторить его своими силами (может быть, сделав это проще/эффективней). В чем состоит принцип интеллекта, аналог законов аэродинамики для полета, мы пока не знаем. Deep learning и Ян Лекун, пророк его (и вслед за ним много других людей) считают, что нужно смотреть в сторону способности строить «глубокие» иерархии фич из получаемых данных. Может быть, мы сможем добавить к этому еще одно уточнение — способность объединять вместе релевантные куски данных, воспринимая их как части одного объекта и размещая в новом измерении?
habr.com
Пару слов о распознавании образов / Хабр
Давно хотел написать общую статью, содержащую в себе самые основы Image Recognition, некий гайд по базовым методам, рассказывающий, когда их применять, какие задачи они решают, что возможно сделать вечером на коленке, а о чём лучше и не думать, не имея команды человек в 20. Какие-то статьи по Optical Recognition я пишу давненько, так что пару раз в месяц мне пишут различные люди с вопросами по этой тематике. Иногда создаётся ощущение, что живёшь с ними в разных мирах. С одной стороны понимаешь, что человек скорее всего профессионал в смежной теме, но в методах оптического распознавания знает очень мало. И самое обидное, что он пытается применить метод из близрасположенной области знаний, который логичен, но в Image Recognition полностью не работает, но не понимает этого и сильно обижается, если ему начать рассказывать что-нибудь с самых основ. А учитывая, что рассказывать с основ — много времени, которого часто нет, становится всё ещё печальнее. Эта статья задумана для того, чтобы человек, который никогда не занимался методами распознавания изображений, смог в течении 10-15 минут создать у себя в голове некую базовую картину мира, соответствующую тематике, и понять в какую сторону ему копать. Многие методы, которые тут описаны, применимы к радиолокации и аудио-обработке. Начну с пары принципов, которые мы всегда начинаем рассказывать потенциальному заказчику, или человеку, который хочет начать заниматься Optical Recognition:
Какие-то статьи по Optical Recognition я пишу давненько, так что пару раз в месяц мне пишут различные люди с вопросами по этой тематике. Иногда создаётся ощущение, что живёшь с ними в разных мирах. С одной стороны понимаешь, что человек скорее всего профессионал в смежной теме, но в методах оптического распознавания знает очень мало. И самое обидное, что он пытается применить метод из близрасположенной области знаний, который логичен, но в Image Recognition полностью не работает, но не понимает этого и сильно обижается, если ему начать рассказывать что-нибудь с самых основ. А учитывая, что рассказывать с основ — много времени, которого часто нет, становится всё ещё печальнее. Эта статья задумана для того, чтобы человек, который никогда не занимался методами распознавания изображений, смог в течении 10-15 минут создать у себя в голове некую базовую картину мира, соответствующую тематике, и понять в какую сторону ему копать. Многие методы, которые тут описаны, применимы к радиолокации и аудио-обработке. Начну с пары принципов, которые мы всегда начинаем рассказывать потенциальному заказчику, или человеку, который хочет начать заниматься Optical Recognition:- При решении задачи всегда идти от простейшего. Гораздо проще повесить на персону метку оранжевого цвета, чем следить за человеком, выделяя его каскадами. Гораздо проще взять камеру с большим разрешением, чем разрабатывать сверхразрешающий алгоритм.
- Строгая постановка задачи в методах оптического распознавания на порядки важнее, чем в задачах системного программирования: одно лишнее слово в ТЗ может добавить 50% работы.
- В задачах распознавания нет универсальных решений. Нельзя сделать алгоритм, который будет просто «распознавать любую надпись». Табличка на улице и лист текста — это принципиально разные объекты. Наверное, можно сделать общий алгоритм(вот хороший пример от гугла), но это будет требовать огромного труда большой команды и состоять из десятков различных подпрограмм.
- OpenCV — это библия, в которой есть множество методов, и с помощью которой можно решить 50% от объёма почти любой задачи, но OpenCV — это лишь малая часть того, что в реальности можно сделать. В одном исследовании в выводах было написано: «Задача не решается методами OpenCV, следовательно, она неразрешима». Старайтесь избегать такого, не лениться и трезво оценивать текущую задачу каждый раз с нуля, не используя OpenCV-шаблоны.
Список приведённых тут методов не полон. Предлагаю в комментариях добавлять критические методы, которые я не написал и приписывать каждому по 2-3 сопроводительных слова.
Часть 1. Фильтрация
В эту группу я поместил методы, которые позволяют выделить на изображениях интересующие области, без их анализа. Большая часть этих методов применяет какое-то единое преобразование ко всем точкам изображения. На уровне фильтрации анализ изображения не производится, но точки, которые проходят фильтрацию, можно рассматривать как области с особыми характеристиками.Бинаризация по порогу, выбор области гистограммы
Самое просто преобразование — это бинаризация изображения по порогу. Для RGB изображения и изображения в градациях серого порогом является значение цвета. Встречаются идеальные задачи, в которых такого преобразования достаточно. Предположим, нужно автоматически выделить предметы на белом листе бумаги:
 Выбор порога, по которому происходит бинаризация, во многом определяет процесс самой бинаризации. В данном случае, изображение было бинаризовано по среднему цвету. Обычно бинаризация осуществляется с помощью алгоритма, который адаптивно выбирает порог. Таким алгоритмом может быть выбор матожидания или моды. А можно выбрать наибольший пик гистограммы.
Выбор порога, по которому происходит бинаризация, во многом определяет процесс самой бинаризации. В данном случае, изображение было бинаризовано по среднему цвету. Обычно бинаризация осуществляется с помощью алгоритма, который адаптивно выбирает порог. Таким алгоритмом может быть выбор матожидания или моды. А можно выбрать наибольший пик гистограммы.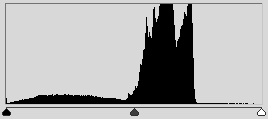 Бинаризация может дать очень интересные результаты при работе с гистограммами, в том числе в ситуации, если мы рассматриваем изображение не в RGB, а в HSV . Например, сегментировать интересующие цвета. На этом принципе можно построить как детектор метки так и детектор кожи человека.
Бинаризация может дать очень интересные результаты при работе с гистограммами, в том числе в ситуации, если мы рассматриваем изображение не в RGB, а в HSV . Например, сегментировать интересующие цвета. На этом принципе можно построить как детектор метки так и детектор кожи человека.

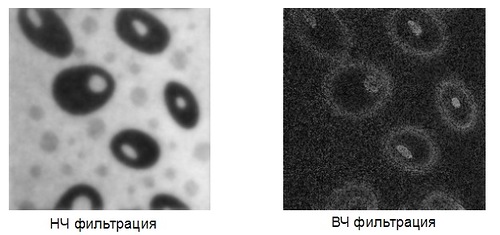
Классическая фильтрация: Фурье, ФНЧ, ФВЧ
Классические методы фильтрации из радиолокации и обработки сигналов можно с успехом применять во множестве задач Pattern Recognition. Традиционным методом в радиолокации, который почти не используется в изображениях в чистом виде, является преобразование Фурье (конкретнее — БПФ ). Одно из немногих исключение, при которых используется одномерное преобразование Фурье, — компрессия изображений. Для анализа изображений одномерного преобразования обычно не хватает, нужно использовать куда более ресурсоёмкое двумерное преобразование.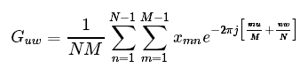 Мало кто его в действительности рассчитывает, обычно, куда быстрее и проще использовать свёртку интересующей области с уже готовым фильтром, заточенным на высокие (ФВЧ) или низкие(ФНЧ) частоты. Такой метод, конечно, не позволяет сделать анализ спектра, но в конкретной задаче видеообработки обычно нужен не анализ, а результат.
Мало кто его в действительности рассчитывает, обычно, куда быстрее и проще использовать свёртку интересующей области с уже готовым фильтром, заточенным на высокие (ФВЧ) или низкие(ФНЧ) частоты. Такой метод, конечно, не позволяет сделать анализ спектра, но в конкретной задаче видеообработки обычно нужен не анализ, а результат.
 Самые простые примеры фильтров, реализующих подчёркивание низких частот (фильтр Гаусса) и высоких частот (Фильтр Габора). Для каждой точки изображения выбирается окно и перемножается с фильтром того же размера. Результатом такой свёртки является новое значение точки. При реализации ФНЧ и ФВЧ получаются изображения такого типа:
Самые простые примеры фильтров, реализующих подчёркивание низких частот (фильтр Гаусса) и высоких частот (Фильтр Габора). Для каждой точки изображения выбирается окно и перемножается с фильтром того же размера. Результатом такой свёртки является новое значение точки. При реализации ФНЧ и ФВЧ получаются изображения такого типа:
Вейвлеты
Но что если использовать для свёртки с сигналом некую произвольную характеристическую функцию? Тогда это будет называться "Вейвлет-преобразование". Это определение вейвлетов не является корректным, но традиционно сложилось, что во многих командах вейвлет-анализом называется поиск произвольного паттерна на изображении при помощи свёртки с моделью этого паттерна. Существует набор классических функций, используемых в вейвлет-анализе. К ним относятся вейвлет Хаара, вейвлет Морле, вейвлет мексиканская шляпа, и.т.д. Примитивы Хаара, про которые было несколько моих прошлых статей (1, 2), относятся к таким функциям для двумерного пространства.
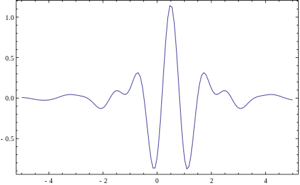
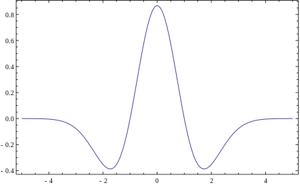
 Выше приведено 4 примера классических вейвлетов. 3х-мерный вейвлет Хаара, 2х-мерные вейвлет Мейера, вейвлет Мексиканская Шляпа, вейвлет Добеши. Хорошим примером использования расширеной трактовки вейвлетов является задачка поиска блика в глазу, для которой вейвлетом является сам блик:
Выше приведено 4 примера классических вейвлетов. 3х-мерный вейвлет Хаара, 2х-мерные вейвлет Мейера, вейвлет Мексиканская Шляпа, вейвлет Добеши. Хорошим примером использования расширеной трактовки вейвлетов является задачка поиска блика в глазу, для которой вейвлетом является сам блик: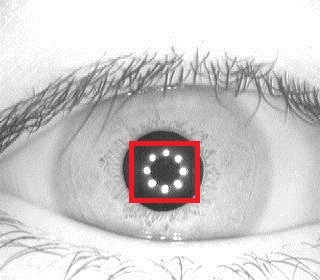 Классические вейвлеты обычно используются для сжатия изображений, или для их классификации (будет описано ниже).
Классические вейвлеты обычно используются для сжатия изображений, или для их классификации (будет описано ниже). Корреляция
После такой вольной трактовки вейвлетов с моей стороны стоит упомянуть собственно корреляцию, лежащую в их основе. При фильтрации изображений это незаменимый инструмент. Классическое применение — корреляция видеопотока для нахождения сдвигов или оптических потоков. Простейший детектор сдвига — тоже в каком-то смысле разностный коррелятор. Там где изображения не коррелируют — было движение.


Фильтрации функций
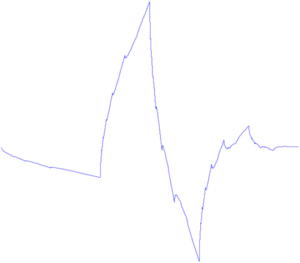
Интересным классом фильтров является фильтрация функций. Это чисто математические фильтры, которые позволяют обнаружить простую математическую функцию на изображении (прямую, параболу, круг). Строится аккумулирующее изображение, в котором для каждой точки исходного изображения отрисовывается множество функций, её порождающих. Наиболее классическим преобразованием является преобразование Хафа для прямых. В этом преобразовании для каждой точки (x;y) отрисовывается множество точек (a;b) прямой y=ax+b, для которых верно равенство. Получаются красивые картинки: (первый плюсег тому, кто первый найдёт подвох в картинке и таком определении и объяснит его, второй плюсег тому, кто первый скажет что тут изображено) Преобразование Хафа позволяет находить любые параметризуемые функции. Например окружности. Есть модифицированное преобразование, которое позволяет искать любые фигуры. Это преобразование ужасно любят математики. Но вот при обработке изображений, оно, к сожалению, работает далеко не всегда. Очень медленная скорость работы, очень высокая чувствительность к качеству бинаризации. Даже в идеальных ситуациях я предпочитал обходиться другими методами.Аналогом преобразования Хафа для прямых является преобразование Радона . Оно вычисляется через БПФ, что даёт выигрыш производительности в ситуации, когда точек очень много. К тому же его возможно применять к не бинаризованному изображению.
(первый плюсег тому, кто первый найдёт подвох в картинке и таком определении и объяснит его, второй плюсег тому, кто первый скажет что тут изображено) Преобразование Хафа позволяет находить любые параметризуемые функции. Например окружности. Есть модифицированное преобразование, которое позволяет искать любые фигуры. Это преобразование ужасно любят математики. Но вот при обработке изображений, оно, к сожалению, работает далеко не всегда. Очень медленная скорость работы, очень высокая чувствительность к качеству бинаризации. Даже в идеальных ситуациях я предпочитал обходиться другими методами.Аналогом преобразования Хафа для прямых является преобразование Радона . Оно вычисляется через БПФ, что даёт выигрыш производительности в ситуации, когда точек очень много. К тому же его возможно применять к не бинаризованному изображению.Фильтрации контуров
Отдельный класс фильтров — фильтрация границ и контуров . Контуры очень полезны, когда мы хотим перейти от работы с изображением к работе с объектами на этом изображении. Когда объект достаточно сложный, но хорошо выделяемый, то зачастую единственным способом работы с ним является выделение его контуров. Существует целый ряд алгоритмов, решающих задачу фильтрации контуров: Чаще всего используется именно Кэнни, который хорошо работает и реализация которого есть в OpenCV (Собель там тоже есть, но он хуже ищёт контуры).

Прочие фильтры
Сверху приведены фильтры, модификации которых помогают решить 80-90% задач. Но кроме них есть более редкие фильтры, используемые в локальных задачах. Таких фильтров десятки, я не буду приводить их все. Интересными являются итерационные фильтры (например активная модель внешнего вида), а так же риджлет и курвлет преобразования, являющиеся сплавом классической вейвлет фильтрации и анализом в поле радон-преобразования. Бимлет-преобразование красиво работает на границе вейвлет преобразования и логического анализа, позволяя выделить контуры: Но эти преобразования весьма специфичны и заточены под редкие задачи.
Но эти преобразования весьма специфичны и заточены под редкие задачи.Часть 2. Логическая обработка результатов фильтрации
Фильтрация даёт набор пригодных для обработки данных. Но зачастую нельзя просто взять и использовать эти данные без их обработки. В этом разделе будет несколько классических методов, позволяющих перейти от изображения к свойствам объектов, или к самим объектам.Морфология
Переходом от фильтрации к логике, на мой взгляд, являются методы математической морфологии (1, 2 , 3). По сути, это простейшие операции наращивания и эрозии бинарных изображений. Эти методы позволяют убрать шумы из бинарного изображения, увеличив или уменьшив имеющиеся элементы. На базе математической морфологии существуют алгоритмы оконтуривания, но обычно пользуются какими-то гибридными алгоритмами или алгоритмами в связке.
Контурный анализ
В разделе по фильтрации уже упоминались алгоритмы получения границ. Полученные границы достаточно просто преобразуются в контуры. Для алгоритма Кэнни это происходит автоматически, для остальных алгоритмов требуется дополнительная бинаризация. Получить контур для бинарного алгоритма можно например алгоритмом жука. Контур является уникальной характеристикой объекта. Часто это позволяет идентифицировать объект по контуру. Существует мощный математический аппарат, позволяющий это сделать. Аппарат называется контурным анализом (1, 2 ). Если честно, то у меня ни разу ни получилось применить контурный анализ в реальных задачах. Уж слишком идеальные условия требуются. То граница не найдётся, то шумов слишком много. Но, если нужно что-то распознавать в идеальных условиях — то контурный анализ замечательный вариант. Очень быстро работает, красивая математика и понятная логика.
Если честно, то у меня ни разу ни получилось применить контурный анализ в реальных задачах. Уж слишком идеальные условия требуются. То граница не найдётся, то шумов слишком много. Но, если нужно что-то распознавать в идеальных условиях — то контурный анализ замечательный вариант. Очень быстро работает, красивая математика и понятная логика.Особые точки
Особые точки это уникальные характеристики объекта, которые позволяют сопоставлять объект сам с собой или с похожими классами объектов. Существует несколько десятков способов позволяющих выделить такие точки. Некоторые способы выделяют особые точки в соседних кадрах, некоторые через большой промежуток времени и при смене освещения, некоторые позволяют найти особые точки, которые остаются таковыми даже при поворотах объекта. Начнём с методов, позволяющих найти особые точки, которые не такие стабильные, зато быстро рассчитываются, а потом пойдём по возрастанию сложности:Первый класс. Особые точки, являющиеся стабильными на протяжении секунд. Такие точки служат для того, чтобы вести объект между соседними кадрами видео, или для сведения изображения с соседних камер. К таким точкам можно отнести локальные максимумы изображения, углы на изображении (лучший из детекторов, пожалуй, детектор Хариса), точки в которых достигается максимумы дисперсии, определённые градиенты и.т.д.Второй класс. Особые точки, являющиеся стабильными при смене освещения и небольших движениях объекта. Такие точки служат в первую очередь для обучения и последующей классификации типов объектов. Например, классификатор пешехода или классификатор лица — это продукт системы, построенной именно на таких точках. Некоторые из ранее упомянутых вейвлетов могут являются базой для таких точек. Например, примитивы Хаара, поиск бликов, поиск прочих специфических функций. К таким точкам относятся точки, найденные методом гистограмм направленных градиентов (HOG).Третий класс. Стабильные точки. Мне известно лишь про два метода, которые дают полную стабильность и про их модификации. Это SURF и SIFT. Они позволяют находить особые точки даже при повороте изображения. Расчёт таких точек осуществляется дольше по сравнению с остальными методами, но достаточно ограниченное время. К сожалению эти методы запатентованы. Хотя, в России патентовать алгоритмы низя, так что для внутреннего рынка пользуйтесь.Часть 3. Обучение
ретья часть рассказа будет посвящена методам, которые не работают непосредственно с изображением, но которые позволяют принимать решения. В основном это различные методы машинного обучения и принятия решений. Недавно Яндыкс выложил на Хабр курс по этой тематике, там очень хорошая подборка. Вот тут оно есть в текстовой версии. Для серьёзного занятия тематикой настоятельно рекомендую посмотреть именно их. Тут я попробую обозначить несколько основных методов используемых именно в распознавании образов. В 80% ситуаций суть обучения в задаче распознавания в следующем: Имеется тестовая выборка, на которой есть несколько классов объектов. Пусть это будет наличие/отсутствие человека на фотографии. Для каждого изображения есть набор признаков, которые были выделены каким-нибудь признаком, будь то Хаар, HOG, SURF или какой-нибудь вейвлет. Алгоритм обучения должен построить такую модель, по которой он сумеет проанализировать новое изображение и принять решение, какой из объектов имеется на изображении. Как это делается? Каждое из тестовых изображений — это точка в пространстве признаков. Её координаты это вес каждого из признаков на изображении. Пусть нашими признаками будут: «Наличие глаз», «Наличие носа», «Наличие двух рук», «Наличие ушей», и.т.д… Все эти признаки мы выделим существующими у нас детекторами, которые обучены на части тела, похожие на людские. Для человека в таком пространстве будет корректной точка [1;1;1;1;..]. Для обезьяны точка [1;0;1;0...] для лошади [1;0;0;0...]. Классификатор обучается по выборке примеров. Но не на всех фотографиях выделились руки, на других нет глаз, а на третьей у обезьяны из-за ошибки классификатора появился человеческий нос. Обучаемый классификатор человека автоматически разбивает пространство признаков таким образом, чтобы сказать: если первый признак лежит в диапазоне 0.5 По существу цель классификатора — отрисовать в пространстве признаков области, характеристические для объектов классификации. Вот так будет выглядеть последовательное приближение к ответу для одного из классификаторов (AdaBoost) в двумерном пространстве: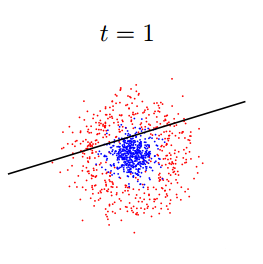
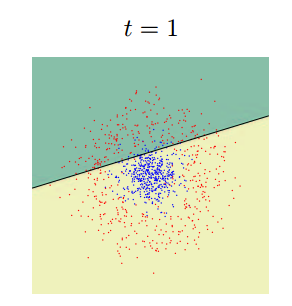
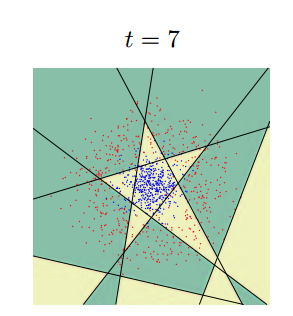
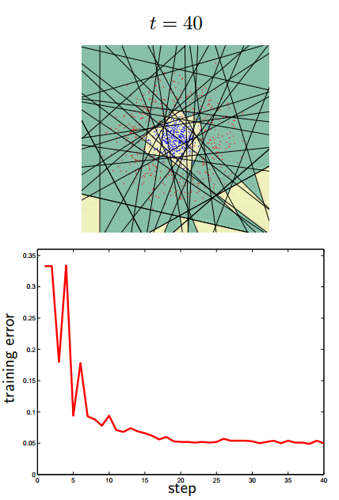 Существует очень много классификаторов. Каждый из них лучше работает в какой-то своей задачке. Задача подбора классификатора к конкретной задаче это во многом искусство. Вот тут немножко красивых картинок на тему.
Существует очень много классификаторов. Каждый из них лучше работает в какой-то своей задачке. Задача подбора классификатора к конкретной задаче это во многом искусство. Вот тут немножко красивых картинок на тему.Простой случай, одномерное разделение
Разберём на примере самый простой случай классификации, когда пространство признака одномерное, а нам нужно разделить 2 класса. Ситуация встречается чаще, чем может представиться: например, когда нужно отличить два сигнала, или сравнить паттерн с образцом. Пусть у нас есть обучающая выборка. При этом получается изображение, где по оси X будет мера похожести, а по оси Y -количество событий с такой мерой. Когда искомый объект похож на себя — получается левая гауссиана. Когда не похож — правая. Значение X=0.4 разделяет выборки так, что ошибочное решение минимизирует вероятность принятия любого неправильного решения. Именно поиском такого разделителя и является задача классификации.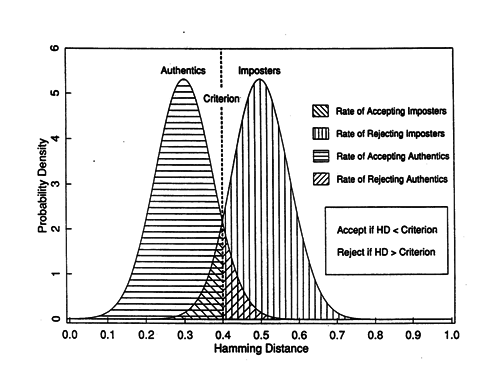 Маленькая ремарка. Далеко не всегда оптимальным будет тот критерий, который минимизирует ошибку. Следующий график — это график реальной системы распознавания по радужной оболочке. Для такой системы критерий выбирается такой, чтобы минимизировать вероятность ложного пропуска постороннего человека на объект. Такая вероятность называется «ошибка первого рода», «вероятность ложной тревоги», «ложное срабатывание». В англоязычной литературе «False Access Rate ».
Маленькая ремарка. Далеко не всегда оптимальным будет тот критерий, который минимизирует ошибку. Следующий график — это график реальной системы распознавания по радужной оболочке. Для такой системы критерий выбирается такой, чтобы минимизировать вероятность ложного пропуска постороннего человека на объект. Такая вероятность называется «ошибка первого рода», «вероятность ложной тревоги», «ложное срабатывание». В англоязычной литературе «False Access Rate ».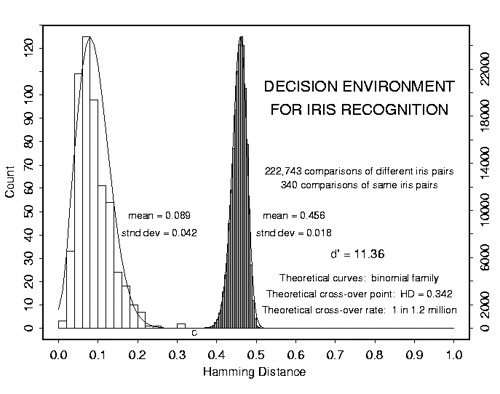
Что делать если измерений больше двух?
Алгоритмов много. Даже очень много. Если хотите подробно узнать про каждый из них читайте курс Воронцова, ссылка на который дана выше, и смотрите лекции Яндыкса. Сказать, какой из алгоритмов лучше для какой задачи часто заранее невозможно. Тут я попробую выделить основные, которые в 90% помогут новичку с первой задачей и реализацию которых на вашем языке программирования вы достоверно найдёте в интернете.k-means (1, 2, 3 ) — один из самых простых алгоритмов обучения. Конечно, он в основном для кластеризации, но и обучить через него тоже можно. Работает в ситуации, когда группы объектов имеют неплохо разнесённый центр масс и не имеют большого пересечения.AdaBoost (1, 2, 3) АдаБуста — один из самых распространённых классификаторов. Например каскад Хаара построен именно на нём. Обычно используют когда нужна бинарная классификация, но ничего не мешает обучить на большее количество классов. SVM (1, 2, 3, 4 ) Один из самых мощных классификаторов, имеющий множество реализаций. В принципе, на задачах обучения, с которыми я сталкивался, он работал аналогично адабусте. Считается достаточно быстрым, но его обучение сложнее, чем у Адабусты и требуется выбор правильного ядра.Ещё есть нейронные сети и регрессия. Но чтобы кратко их классифицировать и показать, чем они отличаются, нужна статья куда больше, чем эта. ________________________________________________ Надеюсь, у меня получилось сделать беглый обзор используемых методов без погружения в математику и описание. Может, кому-то это поможет. Хотя, конечно, статья неполна и нет ни слова ни о работе со стереоизображениями, ни о МНК с фильтром Калмана, ни об адаптивном байесовом подходе. Если статья понравится, то попробую сделать вторую часть с подборкой примеров того, как решаются существующие задачки ImageRecognition.
И напоследок
Что почитать? 1) Когда-то мне очень понравилась книга «Цифровая обработка изображений» Б. Яне, которая написана просто и понятно, но в то же время приведена почти вся математика. Хороша для того, чтобы ознакомиться с существующими методами. 2) Классикой жанра является Р Гонсалес, Р. Вудс " Цифровая обработка изображений ". Почему-то она мне далась сложнее, чем первая. Сильно меньше математики, зато больше методов и картинок. 3) «Обработка и анализ изображений в задачах машинного зрения» — написана на базе курса, читаемого на одной из кафедр ФизТеха. Очень много методов и их подробного описания. Но на мой взгляд в книге есть два больших минуса: книга сильно ориентирована на пакет софта, который к ней прилагается, в книге слишком часто описание простого метода превращается в математические дебри, из которых сложно вынести структурную схему метода. Зато авторы сделали удобный сайт, где представлено почти всё содержание — wiki.technicalvision.ru 4) Почему-то мне кажется, что хорошая книжка, которая структурирует и увязывает картину мира, возникающую при занятии Image Recognition и Machine Learning — это «Об интеллекте» Джеффа Хокинса. Прямых методов там нет, но есть много мыслей на подумать, откуда прямые методы обработки изображений происходят. Когда вчитываешься, понимаешь, что методы работы человеческого мозга ты уже видел, но в задачах обработки видео.habr.com
Онлайн сервисы для бесплатного распознавания текста

Приветствую вас, уважаемые читатели блога Vorabota.ru! Наверное, многие из вас сталкивались с необходимостью распознать текст с какого-нибудь сканированного документа, книги, фотографии и т.д. Как правило, для большого объема распознавания текста с документов используют специальные и довольно дорогие программы (OCR). Но для того, чтобы распознать небольшое количество страниц текста, совсем необязательно покупать дорогостоящее приложение. Есть многим известная бесплатная программа распознавания текста, о которой я уже писал, – CuneiForm. Она простая, удобная, но ее надо устанавливать на компьютер.
А если потребность в распознавании текстов с документов возникает не так часто, то, наверное, будет логичней воспользоваться специальным онлайн сервисом, который распознает текст бесплатно или за символическую сумму. Таких сервисов в интернете можно найти несколько десятков. И, у каждого сервиса, как правило, есть свои плюсы и минусы, которые может определить только сам пользователь.
Для читателей своего блога я решил сделать небольшую подборку онлайн сервисов, на которых можно распознавать тексты с документов разных форматов.
Выбор сделал по следующим критериям:
• Услуга распознания текста должна быть бесплатной.
• Количество распознаваемых страниц текста должно быть неограниченным, а если и есть незначительные ограничения, то не связанные с демонстрацией качества распознавания документа.
• Сервис должен поддерживать распознание русского текста.
Какой сервис распознает тексты лучше, а какой хуже, решать уже вам, уважаемые читатели. Ведь результат, полученный после распознавания текстов, зависит от многих факторов. Это может зависеть от размера исходного документа (страницы, фотографии, рисунка, сканированного текста и т.д.), формата и, конечно же, качества распознаваемого документа.
Итак, у меня получилось шесть сервисов, на которых можно заниматься распознаванием текстов онлайн без каких-либо особых ограничений.
На первое место я поставил сервис Google Диск, где можно сделать распознавание текста онлайн, лишь из-за того, что этот ресурс на русском языке. Все остальные «буржуйские» сервисы на английском языке.
Семь сервисов где можно распознать текст онлайн бесплатно.
 Google Диск
Google Диск
Здесь требуется регистрация, если нет своего аккаунта в Google. Но, если вы когда-то решили создать свой блог на blogspot, то аккаунт у вас уже есть. Можно распознавать изображения PNG, JPG, и GIF и файлы PDF размером не более 2 МБ. В файлах PDF распознаются только первые десять страниц. Распознанные документы можно сохранять в форматах DOC, TXT, PDF, PRT и ODT.
 OCR Convert.
OCR Convert.
Бесплатный онлайн сервис по распознаванию текстов, не требующий регистрации. Поддерживает форматы PDF, GIF, BMP и JPEG. Распознав текст, сохраняет в виде URL ссылки с расширением TXT, который можно скопировать и вставить в нужный вам файл. Позволяет загружать одновременно пять документов объемом до 5 МБ.
 i2OCR.
i2OCR.
На этом онлайн сервисе требуется регистрация. Поддерживает документы для распознавания текстов в формате TIF, JPEG, PNG, BMP, GIF, PBM, PGM, PPM. Можно загружать документ до 10 Мб без каких-либо ограничений. Полученный результат распознавания можно скачать на компьютер в расширении DOC.
 NewOCR.
NewOCR.
На мой взгляд, самый серьезный и отличный онлайн сервис, не требующий регистрации. Без ограничений можно бесплатно распознавать практически любые графические файлы. Загружать сразу по несколько страниц текста в формате TIFF, PDF и DjVu. Может распознавать тексты с изображений в файлах DOC, DOCX, RTF и ODT. Выделять и разворачивать требуемую область текста страницы для распознавания. Поддерживает 58 языков и может сделать перевод текста с помощью Google переводчика онлайн. Сохранить полученные результаты распознавания можно в форматах TXT, DOC, ODT, RTF, PDF, HTML.
 OnlineOcr.
OnlineOcr.
Позволяет без регистрации и бесплатно провести распознавание текста с 15 изображений за один час с максимальным размеров 4 МБ. Вы можете извлечь текст из файлов формата JPG, JPEG, BMP, TIFF, GIF и сохранить на свой компьютер полученный результат в виде документов с расширением MS Word (DOC), MS Excel (XLS) или в текстовом формате TXT. Но для этого придется каждый раз вводить капчу. Поддерживает для распознавания 32 языка.
 FreeOcr.
FreeOcr.
Онлайн сервис для бесплатного распознавания текста, на котором не нужна регистрация. Но для получения результата нужно будет вводить капчу. Распознает по одной странице файлы в формате PDF и изображения JPG, GIF, TIFF или BMP. Есть ограничения на распознавание не более 10 документов в час и размер изображения не должен превышать 5000 пикселей и объем 2 МБ. Распознанный текст можно скопировать и вставить в документ нужного вам формата.
 OCRonline.
OCRonline.
При распознавании текстов на этом онлайн сервисе рекомендуется, чтобы файлы изображений были высокого качества в формате JPG (хотя принимает к распознаванию и другие форматы). Можно распознать только пять страниц текста в неделю, и сохранить на компьютере в формате DOC, PDF, RTF и TXT. Дополнительные страницы распознает только за «буржуйские пиастры» и обязательно нужно зарегистрироваться.
Надеюсь, что эти онлайн сервисы распознавания текста кому-то смогут облегчить трудоемкий процесс набора текстов вручную. Так или иначе, в этих сервисах есть польза. А какой из них лучше или хуже, каждый определит сам для себя.
Буду ждать ваших отзывов. А если кому из читателей понравилась эта подборка сервисов для распознавания текстов, буду весьма благодарен тем, кто поделится ссылкой на эту страницу со своими друзьями. И будет вам и вашим друзьям УДАЧА!
В завершении этой статьи хочу пожелать всем благополучия и успехов. До новых встреч на страницах блога Vorabota.ru
Вас это может заинтересовать:
Голосовой набор текста – онлайн сервисы…
Иногда очень удобно, когда вы просто диктуете текст, а он сам набирается на компьютере. Есть приложения, которые распознают речь и преобразовывают ее в печатный вариант.…
vorabota.ru
Распознавание текста с картинки онлайн бесплатно
 Мы уже рассматривали с Вами программу для распознавания текста с картинки. Но распознавать текст можно не только с помощью программы. Это можно делать с помощью онлайн сервисов, не имея никаких программ на своем компьютере.
Мы уже рассматривали с Вами программу для распознавания текста с картинки. Но распознавать текст можно не только с помощью программы. Это можно делать с помощью онлайн сервисов, не имея никаких программ на своем компьютере.
И действительно, зачем устанавливать какие-то программы, если Вам нужно распознать текст один раз, и в дальнейшем Вы не собираетесь эту программу использовать? Или Вам нужно делать это раз в месяц? В этом случае лишняя программа на компьютере не нужна.
Давайте рассмотрим несколько сервисов, при помощи которых можно распознавать текст с картинки бесплатно, легко и быстро.
Free Online OCR

Очень хорошим сервисом для распознавания текста с картинки онлайн является сервис Free Online OCR. Он не требует регистрации, распознает текст с картинки практически любого формата. работает с 58 языками. Распознаваемость текста у него отличная.
Пользоваться этим сервисом просто. Когда Вы на него зайдете, перед Вами будет всего два варианта: загрузить файл с компьютера, или вставить URL-адрес картинки, если она находится в Интернете.
Если Ваше изображение находится на компьютере, нажимаете на кнопку Выберите файл, затем выбираете свой файл, и нажимаете на кнопку Upload. Вы увидите свой графический файл ниже, а над ним кнопку OCR. Жмете эту кнопку, и получаете текст, который Вы можете найти в нижней части страницы.
Online OCR Net
Также довольно неплохой сервис, который позволяет распознавать тексты с картинок онлайн бесплатно, и без регистрации. Поддерживает он 48 языков, включая русский, китайский, корейский и японский. Чтобы начать с ним работать, заходите на Online OCR, нажимаете кнопку Select file, и выбираете файл на своем компьютере. Существуют ограничения по размеру — файл не должен весить больше 5 Мбайт.
В соседних полях выбираете язык и расширение текстового документа, в котором будет полученный из картинки текст. После этого вводите капчу внизу, и нажимаете на кнопку Convert справа.
Внизу появится текст, который Вы можете скопировать, а выше текста — ссылка на загрузку файла с этим текстом.ABBYY FineReader Online
Очень хороший сервис в плане своей многофункциональности. На ABBYY FineReader Online можно не только распознавать текст с картинки, но также и переводит документы из формата PDF в формат Word, переводить таблицы из картинок в Excel, и создавать документы PDF из сканов.
На этом сервисе есть регистрация, но можно обойтись и входом с помощью социальной сети Facebook, сервисов Google+, или Microsoft Account.
Преимущество такого подхода в том, что созданные документы будут храниться в Вашем аккаунте в течении 14 дней, и даже если Вы их удалите из компьютера, можно будет вернуться на сервис, и опять их скачать.
Online OCR Ru
Сервис, похожий на предыдущий, с информацией на русском языке. Принцип работы сервиса Online OCR такой же, как и всех остальных — нажимаете на кнопку Выберите файл, загружаете картинку, выбираете язык и выходной формат текстового документа, и нажимаете на кнопку Распознать текст.

Кроме распознавания текста из картинок, сервис предоставляет возможность перевода изображений в форматы PDF, Excel, HTML и другие, причем структура и разметка документа будет соответствовать той, которая была на картинке.
На этом сервисе также есть регистрация, и файлы, созданные Вами с его помощью, будут храниться в Вашем личном кабинете.
Данные сервисы распознавания текста с картинок, на мой взгляд, самые лучшие. Надеюсь, они и Вам принесут пользу. Также, возможно, я не все хорошие сервисы осветил. Жду Ваших комментариев, насколько эти сервисы Вам понравились, какими сервисами пользуетесь Вы, и какие из них являются, на Ваш взгляд, самыми удобными.
Более подробные сведения Вы можете получить в разделах "Все курсы" и "Полезности", в которые можно перейти через верхнее меню сайта. В этих разделах статьи сгруппированы по тематикам в блоки, содержащие максимально развернутую (насколько это было возможно) информацию по различным темам.
Также Вы можете подписаться на блог, и узнавать о всех новых статьях. Это не займет много времени. Просто нажмите на ссылку ниже: Подписаться на блог: Дорога к Бизнесу за Компьютером
Проголосуйте и поделитесь с друзьями анонсом статьи на Facebook:
pro444.ru
Как распознать текст с картинки

Все чаще мы встречаемся в жизни с ситуацией, когда нужно перевести какой-либо текст, содержащийся в файлах формата изображений, в электронную текстовую форму. Для того, чтобы сэкономить время, и не перепечатывать вручную, существуют специальные компьютерные приложения для распознавания текста. Но, к сожалению, не каждый пользователь умеет с ними работать. Давайте пошагово выясним, как распознать текст с картинки при помощи самой популярной программы для оцифровки ABBYY FineReader.
Это условно-бесплатное приложение от российского разработчика обладает огромнейшим функционалом, и способно не только распознавать текст, но и производить его редактирование, сохранение в различных форматах, и сканирование бумажных исходников.
Скачать ABBYY FineReader
Установка программы
Установка ABBYY FineReader довольно проста, и не отличается от инсталляции большинства подобных продуктов. Единственное на чем нужно акцентировать внимание, так это на том, что после запуска скачанного с официального сайта исполняемого файла, происходит его распаковка. После этого, запускается установщик, в котором все вопросы и рекомендации представлены на русском языке.

Дальнейший процесс установки довольно прост и понятен, так что не будем заострять на нем внимание.
Загрузка картинки
Чтобы распознать текст на картинке, прежде всего, нужно загрузить её в программу. Для этого, после запуска ABBYY FineReader, жмем на кнопку «Открыть», расположенную в верхнем горизонтальном меню.

После выполнения данного действия, открывается окно выбора источника, где вы должны найти и открыть нужное вам изображение. Поддерживаются следующие популярные форматы изображений: JPEG, PNG, GIF, TIFF, XPS, BMP и др., а также файлы PDF и Djvu.

Распознавание изображения
После загрузки в ABBYY FineReader, автоматически начинается процесс распознавания текста на картинке без вашего вмешательства.

В случае, если вы хотите произвести повторную процедуру распознавания, то достаточно просто нажать кнопку «Распознать» в верхнем меню.

Редактирование распознанного текста
Иногда, не все символы программа может распознать корректно. Это может быть в том случае, если изображение на исходнике не слишком качественное, очень мелкий шрифт, в тексте используется несколько разных языков, применяются нестандартные символы. Но это не беда, так как ошибки можно исправить вручную, с помощью текстового редактора, и набора инструментов, который он предоставляет.

Для облегчения поиска неточностей оцифровки, программа по умолчанию выделяет возможные ошибки бирюзовым цветом.
Сохранение результатов распознавания
Закономерным окончанием процесса распознавания является сохранение его результатов. Для этого жмем кнопку «Сохранить» на верхней панели меню.

Перед нами появляется окно, где мы можем сами определить место нахождения файла, в котором будет располагаться распознанный текст, а также его формат. Доступны следующие форматы для сохранения: DOC, DOCX, RTF, PDF, ODT, HTML, TXT, XLS, XLSX, PPTX, CSV, FB2, EPUB, Djvu.

Читайте также: Программы для распознавания текста
Как видим, распознать текст с картинки при помощи ABBYY FineReader довольно просто. Данная процедура не потребует от вас много усилий, а польза будет в огромной экономии времени.
 Мы рады, что смогли помочь Вам в решении проблемы. Задайте свой вопрос в комментариях, подробно расписав суть проблемы. Наши специалисты постараются ответить максимально быстро.
Мы рады, что смогли помочь Вам в решении проблемы. Задайте свой вопрос в комментариях, подробно расписав суть проблемы. Наши специалисты постараются ответить максимально быстро. Помогла ли вам эта статья?
Да Нетlumpics.ru
Онлайн распознавание текста — ТОП-3 сервиса
Онлайн распознавание текста – это процедура извлечения символов из сканированного документа или изображения с помощью веб-программ.
Распознавание слов позволяет пользователю существенно сэкономить время, ведь их не нужно печатать самостоятельно.
Сегодня с помощью оптической технологии распознавания текста OCR массово конвертируется огромное количество отсканированных книг журналов, которые потом можно читать на компьютере.
Оптическое распознавание стало популярным, ведь после процедуры определения символов, текст можно не только прочитать, но и перевести с помощью автоматического переводчика, внести правки и форматировать его, применяя различные стили.

Содержание:
К сожалению, данная технология не может распознать информацию из PDF со стопроцентной точностью.
Поэтому после завершения обработки файла проводится сравнение двух исходных документов (если форматируется большой документ или книга) и корректор вносит правки в полученный текст.
1. Онлайн-словарь для распознавания текста ABBYY
Самая популярная программа-словарь, которая имеет функцию определения текста с изображений и других типов документов.
Данное приложение позволяет пользователю моментально получить тестовый вариант фотографии и перевести его на более чем на 50 языков мира.
Чтобы распознать текст с помощью данного сервиса, следуйте инструкции:
- Зайдите на официальный сайт веб-приложения и нажмите на кнопку «Распознать», которая находится в центре страницы. Официальная ссылка на сервис: https://finereaderonline.com/ru-ru
- Загрузите файл, с которого необходимо распознать инфо;
Процесс добавления картинки, с которой будет определяться текст
Заметьте! Бесплатно программа-сканер может распознать только 10 пользовательских файлов. Размер каждого файла не может превышать 100 МБ.
- Следующим шагом необходимо выбрать язык конечного документа.Даже если вам не нужно переводить текст, выберите необходимый язык, ведь для каждого из них программа выбирает соответствующую кодировку символов, что позволяет более точно отображать символы;

Выбор языка конечного документа
- Последний шаг – необходимо выбрать формат конечного файла. Список доступных форматов указан на картинке ниже.

Список доступных форматов файлов для исходящего документа
С помощью данного сервиса можно переводить текст с PDF в Word, а также с форматов djvu и jpg.
вернуться к меню ↑2. Сервис Online-Ocr
Данный сервис позволяет без регистрации создать текстовый документ из отсканированного файла или из самой обычной картинки.
Данный сервис был первым, кто использовал технологию оптического определения машинного текста.
Приведем пример распознавания с ПДФ в Ворд:
- Зайдите на сайт сервиса: http://www.onlineocr.net/
- Нажмите на клавишу «выбрать файл» и найдите на своем компьютере необходимый пдф документ, с которого будет определен текст. Максимальный размер входящего документа равен пяти мегабайтам;
Внешний вид сервиса ONLINE OCR
- Выберите язык входящего документа и формат конечного файла из предложенного списка поддерживаемых форматов. Нажмите кнопку «Конвертировать»;
Процесс конвертации занимает максимум 5 минут, данный показатель зависит от размера входящего файла, от его кодировки и сложности визуального оформления.
вернуться к меню ↑3. Веб-приложение Free-OCR
Главное преимущество данного сервиса – возможность работы практически со всеми форматами картинок.
К примеру, большинство сервисов распознавания текста не поддерживают такие форматы, как gif, bmp или tif.
Внешний вид сайта очень простой, таким образом каждый пользователь сможет справиться с поставленной задачей.
Ссылка на сервис: www.free-ocr.com
Внешний вид веб-приложения
Удобнее всего переводить текст в Word, ведь данная программа способна отобразить огромное количество различных текстовых кодировок, а также элементы дизайна входящего файла.
Данный сервис является абсолютно бесплатным и не требует пользовательской регистрации.
Единственное ограничение — размер входящего файла должен быть меньше, чем 6 мегабайт, поэтому распознавать большие документы с помощью данной программы не получиться.
Самое точное направление распознавания – с формата JPEG в ворд.
Тематические видеоролики:
Онлайн распознавание текста — ТОП-3 сервиса
Проголосовать8 Общий итог
Весьма простые сервисы для онлайн-распознавания текста с изображений. На их освоение даже не нужно время, ведь там все элементарно и просто. Огромным плюсом является отсутствие необходимости вкладывать в работу с этими сервисами деньги.
Сложность использования
7
Время на освоение
7
geek-nose.com









