Художник от Google. Искусственный интеллект научился писать картины. Нейросети рисуют картины
от инцепционизма к искусству будущего
Новый адрес страницы:https://tannarh.wordpress.com/2015/10/10/нейросети-от-инцепционизма-к-искусст/
Предчувствие грядущего
В 1993 году я увидел по телевизору клип на песню Питера Габриэля "Steam", созданный с использованием весьма продвинутой на тот момент компьютерной графики. Компьютерные спецэффекты уже не были чем-то принципиально новым, хотя и вызывали восторг у большинства постсоветских зрителей, лишенных возможности наблюдать их постепенную эволюцию от «Звездных войн» и «Трона» до «Терминатора 2» и «Газонокосильщика». Счастливые обладатели видеомагнитофонов, к коим принадлежал и я, смотрели все сразу без какой-либо хронологической последовательности. И все же клип Габриэля концептуально отличался от увиденного мною прежде.
 Peter Gabriel "Steam" (1992), James Cameron "Avatar" (2009)
Peter Gabriel "Steam" (1992), James Cameron "Avatar" (2009)В вышедшем годом ранее втором «Терминаторе», равно как и во многих других тогдашних голливудских фильмах, компьютерная графика использовалась лишь в качестве спецэффектов, дополняющих привычную реальность. Однако в "Steam" с ее помощью был создан целый мир со своими персонажами, никоим образом не пересекающийся с действительностью, как, скажем, в «Газонокосильщике», где виртуальная реальность существовала внутри реального мира в качестве компьютерной модели.
Конечно, графика 1992 года была донельзя примитивной и привлекала внимание скорее своей необычностью, нежели мастерством исполнения, и все же, помню, я подумал, что у этой технологии есть огромный потенциал, который изменит все наши представления о кинематографе и искусстве вообще. Спустя всего семнадцать лет (пустяковый по историческим меркам срок) Джеймс Кэмерон снял фильм «Аватар», объединив фантазию и технологии в демиургическом акте творения новой вселенной. И даже сейчас, по прошествии более чем двух десятилетий после "Steam" и «Газонокосильщика», потенциал компьютерных технологий еще не раскрыт в полной мере ни в кинематографе, ни в других сферах человеческой деятельности. Когда-нибудь «Аватар» будут смотреть с той же вежливой снисходительностью, с какой мы сегодня пересматриваем старые фантастические фильмы начала 90-х, и эта история будет повторяться снова и снова, хотя сама компьютерная графика уже не будет пробуждать в душе ощущение чуда.
Ощущение чуда и гигантского потенциала, скрытого за примитивной на вид игрой образов, вернулось ко мне летом 2015-ого, когда новостные ленты наперебой начали сообщать о последних успехах ученых в разработке искусственных нейронных сетей, и я снова подумал, что сам того не ведая, прикоснулся к будущему, которое в скором времени кардинальным образом изменит наши взгляды на искусство и сам процесс творчества. А начнется все, пожалуй, с этой небольшой анимации, напоминающей фильм «Помутнение» (2006) с Киану Ривзом:

Первые успехи
Одно из главных преимуществ искусственных нейронных сетей перед обычными алгоритмами заключается в том, что их не программируют, а обучают. Структурно они похожи на нейронные сети живых организмов и представляют собой систему соединенных и взаимодействующих между собой искусственных нейронов, способных принимать решения на основе полученной информации и решать весьма сложные задачи. В процессе обучения нейронная сеть способна выявлять сложные зависимости между входными данными и выходными, а также выполнять обобщение. Кроме того, некоторые исследователи задумываются о возможности развития психологической интуиции у нейросетей и о построении на их основе компьютерных моделей естественного интеллекта.[1]
Что все это означает на практике? Вот лишь некоторые из новостей последних лет:
«Недавно разработчики добавили функцию визуального перевода в Google Translate. Теперь приложение может при помощи камеры на лету переводить надписи на 27 языках даже без подключения к интернету. Об этом сообщается в официальном блоге Google. Специалисты Google тренировали нейросеть на изображении букв и цифр, которые в различной степени намеренно искажали. После этого разработчики Google намеренно «ослабили» сложность нейросети, занимающейся распознаванием букв. Например, нейросеть не будет распознавать перевернутые набок надписи или совсем искаженные буквы.
 Искаженные буквы, использованные при обучении нейросети.Изображение: Google
Искаженные буквы, использованные при обучении нейросети.Изображение: GoogleПосле того, как нейросеть распознала буквы, приложение составляет из них слово и проверяет его через загруженные в память телефона словари. При этом учитывается визуальная схожесть символов, поэтому приложение, например, при распознавании последовательности символов «5uper» проверит в словаре не только его, но и «Super».[2]
«Facebook опубликовала научную работу, описывающую созданную исследователями компании систему распознавания лиц при помощи глубокого обучения (deep learning). По точности узнавания она вплотную приблизилась к человеческим способностям.
До сих пор люди различали лица из этого набора куда лучше, чем это делают машины. В 97,53% случаев они верно узнавали фотографии, изображающие одного человека. Алгоритм Deepface отстаёт совсем немного: его точность составляет 97,25%. При этом не играет роли, с какого ракурса сделан снимок и совпадает ли освещённость.
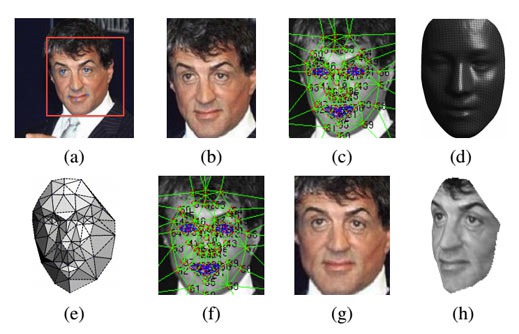
Распознавание происходит в два этапа. На первом Deepface накладывает лицо с фотографии на трёхмерную модель средней человеческой головы, а потом разворачивает её в том же направлении, что и на других портретах. Затем к работе подключается заранее обученная многослойная нейронная сеть и даёт лицу числовое описание. Если описания двух лиц совпадают, они, как правило, принадлежат одному человеку. Нейронная сеть состоит из девяти слоёв нейронов, между которыми проходят 120 миллионов связей. Сеть обучали на четырёх миллионах портретах, принадлежащих примерно четырём тысячам пользователей Facebook».[3]
«Ученые из Технологического института Карлсруэ разработали алгоритм, способный опознать человека по инфракрасному изображению низкого разрешения. Результаты исследования опубликованы на сайте arXiv.org, с кратким описанием можно ознакомиться в MIT Technology Review.
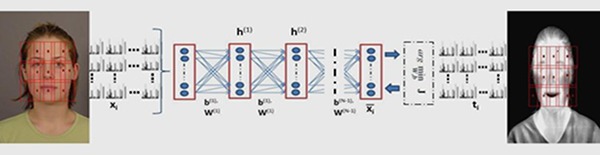 Сопоставление фотографии и ИК-изображения человека.Изображение: M. Saquib Sarfraz, Rainer Stiefelhagen / Institute of Anthropomatics & Robotics Karlsruhe institute of Technology Karlsruhe
Сопоставление фотографии и ИК-изображения человека.Изображение: M. Saquib Sarfraz, Rainer Stiefelhagen / Institute of Anthropomatics & Robotics Karlsruhe institute of Technology KarlsruheЧеловеческое лицо может выглядеть абсолютно по-разному в инфракрасном диапазоне в зависимости от температуры воздуха и кожи. К тому же, большая часть камер, оборудованных инфракрасными матрицами, выдают изображение низкого разрешения. Для решения этой задачи исследователи использовали глубинное обучение нейросети.
Создатели обучили нейросеть на базе изображений Университета Нотр-Дам. В базе были данные по 82 людям, 4585 изображений среди которых были обычные фотографий разрешением 1600x1200 и инфракрасные изображения разрешением 312x239. При этом снимки были сделаны в разные времена года и люди вели на разных фотографиях себя по-разному: улыбались, смеялись, наклоняли голову и тому подобное. Исследователи посчитали, что в таких условиях алгоритм сможет лучше распознавать человеческое лицо вне зависимости от того, в какой момент получено ИК-изображение.
В итоге ученые использовали данные половины базы, по 41 человеку, чтобы натренировать нейросеть. Вторую группу изображений авторы работы использовали для проверки функционирования нейросети. В итоге алгоритм показал точность распознавания на 10% выше, чем в результатах аналогичных работ, при этом на распознавание человека у машины уходит всего 35 миллисекунд».[4]
«Греческие ученые научились определять пьяных людей по инфракрасному изображению. Исследование опубликовано в Forensic Science International. Исследователи из Университета Патры обучали нейросети на примере 41 человека, сравнивая инфракрасное изображение лиц испытуемых до и после употребления 480 миллилитров вина. При этом разные нейросети анализировали разные участки лица.
Ученые использовали два подхода. В первом случае изображение разбивалось на небольшие сегменты, которые анализировались по отдельности. Во втором случае алгоритм обрабатывал изображение целиком. Выяснилось, что нейросеть точнее всего определяет пьяного человека по температуре лба и носа. При анализе только этих зон нейросеть определяет употребившего алкоголь человека с точностью выше 90 процентов даже при отсутствии термограммы лица в трезвом состоянии, в то время как при анализе лица целиком точность снижается до 75 процентов.
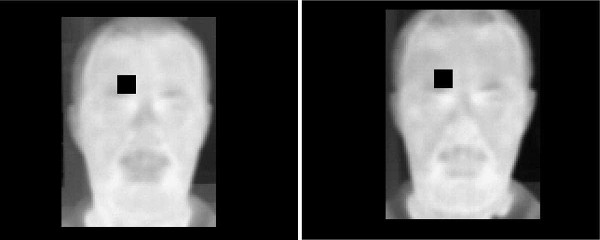 Сравнение одной из зон лица до и после употребления алкоголя.Изображение: Georgia Koukiou et al. / Forensic Science International
Сравнение одной из зон лица до и после употребления алкоголя.Изображение: Georgia Koukiou et al. / Forensic Science InternationalПредполагается, что исследование может помочь полиции выявлять потенциальных нарушителей общественного порядка при помощи инфракрасных камер. Алгоритм также может лечь в основу систем предупреждения вождения в состоянии алкогольного опьянения»[5].
Инцепционизм
Распознавание лиц имеет сугубо прагматическое значение, например, с помощью этой технологии можно искать преступников в больших городах или организовать тотальную слежку за населением, однако настоящий концептуальный прорыв совершила компания Google, создатели которой, кстати, с самого начала не скрывали, что ставят своей целью создание искусственного интеллекта. Вполне возможно, что объединение их разработок с последними достижениями купленной Гуглом в 2013 году компании Boston Dynamics в области робототехники могут привести к весьма любопытным, хотя и пугающим результатам. Сегодня корпорация Google занимается сканированием книг по всему миру, и если однажды она пропустит все накопленные человечеством знания через достаточно мощную нейронную сеть, то в результате мы можем получить технологию, способную перевернуть все наши представления о творчестве и создании произведений искусства. Искусство станет персональным, адаптивным и свободным, что повлечет за собой огромные экономические и социальные изменения.
«Инженеры Google Александр Мордвинцев, Крисофер Ола и Майк Тика визуализовали работу 22-слойной сверточной нейросети, которая составляет основу системы распознавания изображений Inception. Изображения, которые получились в результате «переворачивания системы с ног на голову», исследователи назвали «инцепционизмом». О методе получения таких изображений они рассказали в блоге Google Research.
Общая идея создания таких изображений основана на том, что в фотографии или картине усиливают те черты, которые напоминают системе что-то знакомое. Например, если система натренирована на распознавание лица, она даже в совершенно случайном изображении — например, облаков — увидит какие-то его фрагменты. Затем их можно будет усилить, получив изображения с лицами на облаках.
 Результат нескольких итераций полностью случайного изображения.Изображение: MIT Computer Science and AI Laboratory
Результат нескольких итераций полностью случайного изображения.Изображение: MIT Computer Science and AI LaboratoryС технической точки зрения речь идет об алгоритме обратного распространения значений каждого из нейронов из произвольно выбранного слоя нейросети. Подав на вводный слой случайное изображение, инженеры брали значения из верхнего интересующего их слоя и распространяли значения обратно, искажая исходное изображение — по аналогии со стандартным алгоритмом обратного распространения ошибки, который используется для тренировки нейросети. Смысл такого переворачивания сети заключался в том, что оно позволяло визуализовать веса связей в слое любого уровня. На уровнях выше первого-второго сами по себе веса визуализовать очень сложно: обычно они напоминают белый шум.
 Результат нескольких итераций полностью случайного изображения.Изображение: MIT Computer Science and AI Laboratory
Результат нескольких итераций полностью случайного изображения.Изображение: MIT Computer Science and AI LaboratoryКак и ожидалось, нижние уровни сети находили в исходной картинке простые геометрические черты: наклонные линии, круги и так далее. Слои высокого уровня позволяли увидеть на фотографиях что-то напоминающее людей и животных. С помощью нескольких итераций инженерам удалось получить целые абстрактные картины, стартовав при этом с полностью случайного изображения (строго говоря, изображения не были белым шумом, так как ученым пришлось нормализовать корреляцию между соседними пикселями до типичных значений «обычных изображений»).
Работа сделана на базе архитектуры Inception, по которой в Google построена сверточная нейронная сеть 22 уровнями GoogLeNet. Именно ее инженеры использовали для получения изображений. Ранее тот же подход к визуализации работы нейросетей неоднократно применяли и другие исследователи, однако в их распоряжении не было настолько масштабной системы. Описание системы Inception было опубликовано еще в сентябре прошлого года.
Интересно, что по современным данным нейрофизиологии распознавание изображений мозгом устроено очень похоже: «появление» объекта на картине зависит от порога чувствительности, на который влияют, например, галлюциногены или сенсорная депривация»[6].
«Чтобы нейронная сеть начала рисовать картины на её вход подается изображение рандомного шума и ставится задача — найти в нем определенную форму и утрировать её. Например, нарисовать банан.

Это нужно для того, чтобы понять научилась ли нейронная сеть распознавать тот или иной образ. Например, её обучали узнавать вилку по определенным характеристикам: 2-4 зубца и ручка. При этом форма и цвет предмета не должны влиять на решение.
Хороший способ проверить, действительно ли сеть научилась распознавать образ — это попросить её нарисовать его. В некоторых случаях можно выявить явную ошибку в обучении. Система не смогла нарисовать правильную гантель. Скорее всего, при обучении она видела гантели только в комплекте с рукой.

Нейронной сети можно и не задавать конечный результат. Если на вход подать любую картинку и указать уровень, который будет с ней работать, то он улучшит все, что в его компетенции. Пример отрисовки картинки нижним слоем, отвечающим за края:

Если для интерпретации выбрать более продвинутый слой, то сеть постарается найти в картинке те образы, на которых тренировалась. На вход нейронной сети, которая обучалась на фотках животных подали изображение облаков.

Все, что сеть смогла распознать, она сделала утрированным. Таким образом в облаках образовались необычные животные: собака-бабочка, свинья-улитка, птица-верблюд и собака-рыба.

Эту же технику можно применить для любой другой картинки. Результаты зависят от типа изображения, т.к. установленные свойства склоняют сеть к определенным интерпретациям. Например, линия горизонта замещается пагодами и башнями, очертания деревьев и скал — постройками, а листья превращаются в птиц и насекомых.

Техника обратного рисования дает разработчикам оценить качество распознавания того или иного слоя. Сами разработчики называют эту технику «Inceptionism» (инцепционизм)».[7]
Нейроарт и «игра в бисер»
«Коллектив ученых из Германии разработал искусственную нейронную сеть, которая позволяет «синтезировать» изображение из двух независимых источников: одно из них дает только содержание, другое — только стиль. На основании этого метода авторы обработали фотографию с пейзажем немецкого города Тюбинген, используя стили нескольких знаменитых картин, например «Звездную ночь» Винсента ван Гога и «Крик» Эдварда Мунка. Препринт с описанием работы выложен на arXiv.org.
В основе метода лежит обучение сверточных нейронных сетей на двух различных изображениях и последующее слияние полученных наборов признаков в один. Авторы показали, что содержание и объекты лучше удается описать при помощи крупных слоев нейронной сети, захватывающих большие участки изображения. Однако для описания стиля наоборот, лучше использовать данные слоев сети, которые описывают с локальными участками изображения.
Ученые использовали в работе популярную нейронную сеть VGG-Network. Вначале ее «обучали» на единственной фотографии — пейзаже город Тюбинген, а затем на одной из картин, например, «Звездной ночи». При этом в первом случае набор признаков выбирался с целью распознавания объектов на фотографии, а во-втором — для распознавания текстуры и мелких деталей. Далее при помощи линейной комбинации этих наборов признаков ученые синтезировали новую картинку, по шагам изменяя «исходник» — изображение, где каждый пиксель генерировался при помощи белого шума.
В итоге авторы получали одну и ту же фотографию, искаженную в соответствии с выбранным стилем. При этом ученые показали, что варьируя «вклады» от разных слоев нейронной сети, можно настраивать внешний вид картинке изменять «количество» стилевых элементов на ней. Таким образом можно получить как фотографию, очень близкую к оригиналу, так и изображение с характерной стилевой текстурой, в которой невозможно различить содержание исходного материала.
 Пейзаж города Тюбинген, обработанный в нескольких разных стилях.Изображение: Leon A. Gatys et al./ arXiv.org
Пейзаж города Тюбинген, обработанный в нескольких разных стилях.Изображение: Leon A. Gatys et al./ arXiv.orgБолее того, поскольку система в некотором роде «осмысливает» фотографию и технику художника, в ней можно задать степень выраженности оригинального произведения, с которого она передирает стилистику. Например, так выглядит переход от оригинала Кандинского к пейзажу, сделанному под него:
 arXiv / A Neural Algorithm of Artistic Style / Gatys, et al
arXiv / A Neural Algorithm of Artistic Style / Gatys, et alНовую работу уже опробовал аспирант Стэндфордского университета Андрей Карпатый, который в своем твиттере выложил несколько фотографий, обработанных таким образом. Среди них, например, его портрет в стиле Винсента ван Гога, а также снимок Гэндальфа (Иэна Маккелена) из «Властелина колец» в стиле Пабло Пикассо». [8]
 Фотография Иэна Маккеллена в роли Гэндальфа, обработанная в стиле Пабло Пикассо.Изображение: Andrej Karpathy / Twitter
Фотография Иэна Маккеллена в роли Гэндальфа, обработанная в стиле Пабло Пикассо.Изображение: Andrej Karpathy / Twitter
«Феликс Сунь (Felix Sun), студент из Массачусетского технологического института, создал нейронную сеть, которая способна достраивать мелодию аккордами на основе предварительно «выученного» жанра. В качестве демонстрации автор обучил сеть на подборке регтаймов Скотта Джоплина, а затем использовал ее для аранжировки, например оды «К радости» Бетховена. Сама работа подробно описана в блоге программиста, а исходный код выложен на GitHub.
 Нотная запись аранжировки, созданной при помощи DeepHear.Изображение: Felix Sun / web.mit.edu/felixsun/www
Нотная запись аранжировки, созданной при помощи DeepHear.Изображение: Felix Sun / web.mit.edu/felixsun/wwwПрограмма, которая получила название DeepHear, представляет собой глубокую байесовскую сеть (deep belief network). Такая разновидность искусственных нейросетей часто используется для распознавания данных, например, изображений. Однако, в отличии от этой задачи, использовался автокодирующий вариант: сеть не только сводила входящие данные к меньшему числу измерений (от примерно 5000 бит к 16), но и решала обратную задачу, стремясь как можно точнее воспроизвести «образец».
Феликс обучал нейронную сеть на подборке регтаймов, а затем перестроил ее на новую задачу: теперь программе требовалось на основе заданной композиции создать «регтайм» с мелодией, как можно более похожей на оригинал. Таким образом, нейросеть использовала внутренние параметры, выбранные в ходе первого этапа обучения, но в новой задаче уже опиралась на другой критерий «правильности» результата.
Название «DeepHear», вероятно, выбрано созвучным с «DeepDream» — нейросети от Google, которая на основе заданного изображения создает новую картинку, где все объекты дополнены определенными шаблонами (лицами и глазами). DeepHear, по сути, делает то же самое, но с музыкой. В будущем Феликс планирует использовать более совершенные методы обучения, а также перейти от «виртуального композиторства» к генерации естественных звуков при помощи нейросетей».[9]
Personal Art
Вот каким я вижу один из возможных вариантов развития этой потрясающей технологии. Представьте, что вы возвращаетесь вечером с работы и после ужина хотите почитать что-нибудь интересное. Вы включаете компьютер и запускаете свою персональную нейростудию, после чего даете ей задание сгенерировать рассказ в две тысячи слов, указываете жанр, количество персонажей, их возраст и пол и стиль автора, например Борхеса. Впрочем, можно позволить программе самой выбирать и комбинировать все эти параметры совершенно случайным образом, однако вам сегодня не хочется подобных экспериментов. Пока вы наслаждаетесь чтением, нейростудия создает для вас новый альбом Beatles и одновременно генерирует для вашего ребенка мультфильм с придуманными им накануне героями.
К сожалению треки в стиле Beatles получились недостаточно хорошими, поэтому вы заходите на сайт, где люди со всего мира делятся друг с другом сгенерированным контентом и просматриваете первые строчки чартов. Композиция Чайковский+Rammstein с легкой стилизацией под китайскую музыку кажется вам слишком эклектичной, а вот новая песня в стиле Pink Floyd времен "The Dark Side Of The Moon" получилась просто прекрасной.
Утром вас ждет не только чашка ароматного кофе, но и статья Черчилля о недавних событиях в Афганистане, сдобренная изрядной порцией английского юмора, а в блоге Ницше — несколько хлестких афоризмов о внешней политике текушего правительства. В новостях сообщают о новой выставке работ Сальвадора Дали, отобранных профессиональными критиками и искусствоведами из нескольких тысяч работ, присланных на конкурс счастливыми обладателями платной подписки на нейросеть "Dali" от компании Microsoft. Пожалуй, можно будет сходить на выходных, тем более что эта разработка редмондовцев вам пока не по карману, да и в общем-то ни к чему, потому что живописью вы не увлекаетесь.
Закончив завтракать, вы одеваете ваши очки дополнительной реальности от Google, которые превращают все, на что вы смотрите, в красочные галлюцинации, подстраивающиеся в реальном времени под активность вашего мозга, и отправляетесь на работу в Бюро социальной поддержки безработных писателей, художников и музыкантов, где вам предстоит выслушивать бесконечный поток жалоб и воспоминаний о «старых добрых» временах, когда они считали себя незаменимыми властителями умов.
Tannarh, 2015 г.
[1] https://ru.wikipedia.org/wiki/Искусственная_нейронная_сеть [2] https://nplus1.ru/news/2015/07/30/google-translate-27 [3] http://www.computerra.ru/96497/deepface/ [4] https://nplus1.ru/news/2015/0hil7/25/deep-neural-infrared [5] https://nplus1.ru/news/2015/05/05/alabama-song [6] https://nplus1.ru/news/2015/06/19/backprop, https://nplus1.ru/news/2015/07/13/use, https://meduza.io/galleries/2015/06/19/intseptsionizm [7] http://habrahabr.ru/company/io/blog/262267/ [8] https://nplus1.ru/news/2015/08/31/like-van-Gogh, https://slon.ru/posts/56202 [9] https://nplus1.ru/news/2015/09/16/deephearПорядок вывода комментариев: По умолчаниюСначала новыеСначала старые
tannarh.narod.ru
Художник от Google. Искусственный интеллект научился писать картины
В блоге Google опубликован рассказ группы исследователей о том, как искусственные нейронные сети научили писать свои картины. Для этого использовались нейросети, предназначенные для распознавания изображений: получив фотографию или рисунок, они выясняют, какие именно объекты на ней изображены. Такие нейросети состоят из 10–30 связанных слоев, которые работают последовательно: получив картинку, они анализируют ее и «сообщают» результаты анализа следующему слою. Например, первые слои могут искать на изображении края и углы, средние — интерпретировать наборы особенностей в отдельные объекты (например, двери или листья). Наконец, финальные слои объединяют все эти интерпретации воедино и делают выводы о том, что изображено на картинке — например, здание или дерево. Чтобы получать «картины», исследователи заставляют работать нейронные сети задом наперед: они показывают сети случайный шум и просят «улучшить» его таким образом, чтобы на выходе получилась определенная интерпретация. Например, если попросить нейросеть «найти» в шуме банан, муравья или морскую звезду, та действительно подкорректирует изображение, чтобы в нем проявились узнаваемые черты.
Такие нейросети состоят из 10–30 связанных слоев, которые работают последовательно: получив картинку, они анализируют ее и «сообщают» результаты анализа следующему слою. Например, первые слои могут искать на изображении края и углы, средние — интерпретировать наборы особенностей в отдельные объекты (например, двери или листья). Наконец, финальные слои объединяют все эти интерпретации воедино и делают выводы о том, что изображено на картинке — например, здание или дерево. Чтобы получать «картины», исследователи заставляют работать нейронные сети задом наперед: они показывают сети случайный шум и просят «улучшить» его таким образом, чтобы на выходе получилась определенная интерпретация. Например, если попросить нейросеть «найти» в шуме банан, муравья или морскую звезду, та действительно подкорректирует изображение, чтобы в нем проявились узнаваемые черты. Шум превращается в бананы.
Шум превращается в бананы.Цель этого процесса — понять, правильно ли нейросеть интерпретирует те или иные объекты. Дело в том, что нейронные сети обучаются на большом количестве примеров. Можно показать им тысячу фотографий вилок, чтобы они определили нужные характеристики (ручка, четыре зубчика) и научились игнорировать лишние (цвет, форма, положение). И в будущем, если «попросить» нейросеть нарисовать вилку, можно увидеть, насколько хорошо она усвоила «урок». Например, с гантелей одна из таких сетей не справилась: по-видимому, на всех фотографиях, которые ей показывали, гантели были изображены вместе с держащими их руками. Поэтому в собственном «творчестве» нейросеть тоже постаралась изобразить гантели с руками.
 Шум превращается в неправильные гантели.
Шум превращается в неправильные гантели.По словам исследователей, нейронной сети можно вообще не говорить, что именно нужно «нарисовать» — пусть решает сама. В таком случае ей на вход подают случайную картинку или фотографию, выбирают один из слоев нейросети и просят ее улучшить то, что этот слой найдет. Так как у каждого слоя свой уровень абстракции, то каждый раз получаются разные картинки. Например, базовые слои, определяющие края и их положение на картинке, будут накладывать на фотографию мазки или простые орнаменты.
 Фото: вверху Zachi Evenor / Flickr / CC BY 2.0, внизу Günther Noack / Google
Фото: вверху Zachi Evenor / Flickr / CC BY 2.0, внизу Günther Noack / GoogleА ниже — пример того, что получится, если скормить картинку более «продвинутым» слоям нейронной сети, которые ищут целые объекты на картинках. Разработчики как бы говорят нейросети: «Что бы ты ни увидела, мы хотим побольше этого!». В результате, если сети покажется, что облако похоже на птицу, она сделает его еще более похожим.

Эта нейросеть в основном обучалась на изображениях животных, поэтому она попыталась найти их на фотографии. Правда, получилось немного вперемешку — как объясняют разработчики, это из-за того, что данные хранились на таком высоком уровне абстракции (да, мы тоже ничего не поняли, но выглядит красиво).
 Слева направо: Бабочка-пес, свинья-улитка, верблюд-птица и собака-рыба. Иллюстрация: Google
Слева направо: Бабочка-пес, свинья-улитка, верблюд-птица и собака-рыба. Иллюстрация: GoogleРаботает это, конечно, не только с облаками. Ниже другие примеры — как горы превращаются в башни, деревья — в здания, а листочки — в птиц.

Чтобы получить действительно интересные картины, исследователи пошли еще дальше: они подавали нейронной сети картинку, затем то, что она выдала — и так вновь и вновь, на каждом шаге увеличивая масштаб изображения. Причем изначально можно скормить нейросети случайный шум, и все равно получится нечто прекрасное.




























 Все иллюстрации: MIT Computer Science and AI Laboratory / Google
Все иллюстрации: MIT Computer Science and AI Laboratory / Google klikabol.com
Как нейронные сети рисуют картины / СоХабр
Умные алгоритмы уже умеют находить и распознавать лица, определять главную часть картинки, узнавать различные предметы. А нейронные сети пошли дальше и даже могут самостоятельно создавать произведения искусства.Недавно Google на своем блоге опубликовали интересный способ использования нейронных сетей, распознающих картинки. Далее свободный перевод публикации.
Каждая нейронная сеть обучается с помощью миллионов тренировочных картинок. Сеть имеет от 10 до 30 вложенных слоев с различными уровнями абстракции. Вначале картинка поступает на входной слой, который делает свою работу и передает информацию в следующий слой, пока на выходе не получится ожидаемый результат.
Важно понять, что именно происходит на каждом уровне системы. Каждый последующий слой извлекает новые черты изображения. Допустим первый уровень определяет углы и ребра на картинке, второй — формы, и именно последние несколько слоев принимают решение о том, что изображено на картинке.
Распознавание наоборот
Чтобы нейронная сеть начала рисовать картины на её вход подается изображение рандомного шума и ставится задача — найти в нем определенную форму и утрировать её. Например, нарисовать банан.Это нужно для того, чтобы понять научилась ли нейронная сеть распознавать тот или иной образ. Например, её обучали узнавать вилку по определенным характеристикам: 2-4 зубца и ручка. При этом форма и цвет предмета не должны влиять на решение.
Хороший способ проверить, действительно ли сеть научилась распознавать образ — это попросить её нарисовать его.
В некоторых случаях можно выявить явную ошибку в обучении. Система не смогла нарисовать правильную гантель. Скорее всего, при обучении она видела гантели только в комплекте с рукой.
Нижние слои
Нейронной сети можно и не задавать конечный результат. Если на вход подать любую картинку и указать уровень, который будет с ней работать, то он улучшит все, что в его компетенции. Пример отрисовки картинки нижним слоем, отвечающим за края:Продвинутые слои
Если для интерпретации выбрать более продвинутый слой, то сеть постарается найти в картинке те образы, на которых тренировалась.На вход нейронной сети, которая обучалась на фотках животных подали изображение облаков.
Все, что сеть смогла распознать, она сделала утрированным. Таким образом в облаках образовались необычные животные: собака-бабочка, свинья-улитка, птица-верблюд и собака-рыба.
Эту же технику можно применить для любой другой картинки. Результаты зависят от типа изображения, т.к. установленные свойства склоняют сеть к определенным интерпретациям.
Например, линия горизонта замещается пагодами и башнями, очертания деревьев и скал — постройками, а листья превращаются в птиц и насекомых.
Техника обратного рисования дает разработчикам оценить качество распознавания того или иного слоя.
Сами разработчики называют эту технику «Inceptionism» (инцепционизм). Еще картины.
Итерации
На вход нейронной сеть можно подавать немного увеличенную картинку с выхода и получить невероятные цветовые пространства. Если начать с рандомного шума, то выходную картину можно считать исключительно творением нейронной сети.Эта техника помогает понять и визуализировать как именно нейронная сеть выполняет задачи классификации, как улучшить архитектуру и проверить чему она научилась.
Конспект
- Нейронная сеть имеет от 10 до 30 вложенных слоев с разным уровнем абстракции.
- Чтобы нейронная сеть начала рисовать картины на её вход подается картинка и ставится задача — найти в нем определенную форму и утрировать её.
- Техника «инцепционизм» помогает понять и визуализировать как нейронная сеть выполняет задачи классификации.
sohabr.net
Как нейронные сети Google видят изображения
Инженеры Google Александр Мордвинцев, Крисофер Ола и Майк Тика поделились в блоге Google Research удивительными изображениями.
Картинки, состоящие из множества разноцветных мелких деталей и напоминающие где-то полотна Ван Гога, где-то – описания мистических видений, были получены с помощью метода, который ученые окрестили «инцепционизмом». Это визуализация работы 22-слойной нейросети, которая лежит в основе системы распознавания изображений Inception.
Нейросети, с помощью которых распознаются изображения, состоят из 10-30 связанных слоев. В процессе их работы изображение «угадывается» постепенно: сначала распознаются общие формы, границы и углы, затем система определяет предмет на основании собранных особенностей и затем делает вывод об объекте, который может состоять их таких деталей. Например, нейросеть «видит» округлые объекты зеленого цвета, они напоминает ей листья, скопление листьев говорит о том, что на фотографии изображено дерево.
Эксперимент же заключался в том, чтобы перевернуть работу нейросети «с ног на голову» и заставить ее находить изображения в абстракциях и белом шуме.
Нейронные сети обучаются на большом количестве примеров. Например, чтобы знать, что представляет собой то же самое дерево, системе нужно скормить несколько тысяч разных изображений деревьев. Только увидев дерево в тысячах разных варианотов, она сможет понять, что это такое и научится выделять особенности, присущие именно деревьям.
В эксперименте инженеры показали нейросети изображения, близкие к белому шуму, и предложили найти в них различные объекты. Иногда нейросеть просили найти что-то определенное, иногда давали свободу творчества. Здесь, например, систему попросили нарисовать банан, и в некоторых скоплениях точек нейросеть увидела сходства с бананом.
В любой картинке система будет усиливать хорошо знакомые ей черты. Нейросеть, которую тренировали на распознавание животных, будет всюду видеть черты глаза и мордочки, а натренированная, к примеру, на восточную архитектуру, преобразует абстракции в пагоды и храмы.
То, какое у системы получится изображение, зависит от выбранного для распознавания слоя. Базовые слои найдут только общие формы и простые геометрические фигуры (как на фотографии с антилопами выше), зато более высокие увидят на любой фотографии сложные объекы. Вот что, например, нейросеть увидела на фотографии облаков.
Примеры преобразования изображений системой: линия горизонта превращается в башни и пагоды, деревья – в здания, листья – в птиц и насекомых.
В горном пейзаже система увидела архитектурный ансамбль.
Различные орнаменты, увиденные системой.
Система ищет знакомые черты в картине Жоржа Сёра.
С помощью нескольких итераций инженерам удалось получить сложные абстрактные картины с множеством деталей. В этом случае нейронной сети несколько раз отдавали картинку, нарисованную ей самой. В основе мог быть тот же белый шум.
Рисунок, полученный с помощью нескольких итераций.
Рисунок, полученный с помощью нескольких итераций.
Рисунок, полученный с помощью нескольких итераций.
Рисунок, полученный с помощью нескольких итераций.
Рисунок, полученный с помощью нескольких итераций.
Рисунок, полученный с помощью нескольких итераций.
Нейрофизиологи отмечают, что система распознавания образов мозгом устроена схожим образом.
deadbees.net
способен ли искусственный интеллект творить? / Блог компании Neurodata Lab / Хабр
С развитием нейросетей им придумывают всё более разнообразные способы применения. С их помощью обучаются автопилоты Tesla, а распознавание лиц используется не только для обработки фотографий приложениями типа Prisma, но и в системах безопасности. Искусственный интеллект учат диагностировать болезни. В конце концов, с его помощью даже выигрывают выборы.Но есть одна сфера, которая традиционно считалась принадлежащей исключительно человеку — творчество. Однако и это утверждение начинают ставить под сомнение. Ли Седоль, проигравший AlphaGo, признался: «Поражение заставило меня засомневаться в человеческой креативности. Когда я увидел, как играет AlphaGo, то усомнился в том, насколько хорошо играю сам». Поэтому в сегодняшнем посте давайте поговорим о том, способны ли роботы ступить на территорию искусства, в пространство креативности, а значит эмоций и восприятия.
/ Flickr / franck injapan / PD
Творчество роботов
Самообучающиеся системы давно начали проверять на креативность. Например, в 1970 году ученые разработали алгоритм, который мог писать прозаические тексты — правда, довольно бессмысленные.С тех пор нейросети научились рисовать картины, сочинять музыку и стихи, а также придумывать сценарии к фильмам. Яндекс учит нейросети записывать музыкальные альбомы, похожие на альбомы популярных групп, и писать стихи в стиле Егора Летова. Принцип действия всех алгоритмов похож: они анализируют огромный массив произведений искусства, а потом на основе полученных закономерностей «создают» свое творение: картину, музыкальную композицию, роман и т. д.
Творчество нейросетей постепенно институционализируется. Так, в 2016 году впервые прошел конкурс художественных произведений, созданных роботами. В этом году главный приз в 40 тыс. долларов выиграл алгоритм PIX18, придуманный Creative Machines Lab: его похвалили за хороший мазок и умение генерировать произведения на базе фотографий, находящихся в его распоряжении.
Так прокомментировали победу в комитете: «Композиция и работа с кистью напоминает Ван Гога. Интересная палитра». Это выглядит как настоящая критика картины начинающего художника.
Восприятие произведений
Картины, созданные алгоритмом DeepDream от Google, считаются практически искусством — в первую очередь именно потому, что их создал искусственный интеллект.Однако есть другой важный вопрос — новизна. По этому критерию мы оцениваем и творения художников. Если алгоритмы не срисовывают или не обрабатывают фотографии, а, например, пишут абстрактные картины, могут ли они действительно создать что-то новое?
На этот вопрос попробовали ответить разработчики из Лаборатории искусственного интеллекта и искусства Ратгерского университета, создав генеративно-состязательную сеть (GAN). Ранее алгоритм учился на основе ответов одного дискриминатора: анализировал картины, рисовал свои и сверял результат. Он продуцировал изображения, похожие на те, что изучал до того.
Команда сделала следующий шаг в развитии сети и добавила второй дискриминатор, соревнующийся с первым. Теперь нейросеть анализирует примерно 81 тысячу картин и, опираясь на такую объемную выборку, формирует список условий, при которых созданная картина может быть отнесена к произведениям искусства. Параллельно второй дискриминатор составляет список стилей и проверяет картину на схожесть с ними – проводит операцию по верификации. Новая картина рождается тогда, когда изображение признается произведением искусства, не идентичным ни одному из существовавших ранее стилей.
Кроме того, нейросети уже способны создавать мульфильмы. Компьютерная программа The Painting Fool, разработанная Саймоном Колтоном (Simon Colton) из Имперского колледжа Лондона, смогла сплести нарисованные ею же изображения в видеоряд.
Система адаптирует специальные решения для автоматизированного создания коллажей, симулируя мазки кисти на холсте. ПО в состоянии имитировать техники рисования, для чего используются возможности многоядерных процессоров — каждый поток контролирует отдельную кисть. Это позволяет «смешивать» кисти в непредсказуемых комбинациях, что приводит к более правдоподобному эффекту.Сам процесс рисования – например, портрета – начинается с разметки областей заинтересованности: глаз, рта, бровей и т. д. Для каждого «региона» программа сегментирует изображение методом neighbourhood-growing и обосновывает границы. Затем The Painting Fool занимается окраской каждого сегмента. Он может «рисовать» карандашами, пастелью, акварелью и мелками, учитывая освещенность, условия среды.
И The Painting Fool — лишь показательный пример, только один представитель «компьютеров искусства». Причем их количество постоянно увеличивается. Одному роботу удалось настолько очаровать аудиторию музыкальной композицией, что они решили, будто её написал человек. А короткий роман, написанный японским роботом, чуть не выиграл литературную премию.
Это подводит нас к важному вопросу — проблеме рецепции искусства смотрящим. Существует ли разница между нашим восприятием произведения, созданного человеком, и тем, что «сгенерировано» роботом? В интернете есть сайт Bot or Not, предлагающий угадать, кто написал то или иное стихотворение — бот или человек. Ответ не всегда очевиден. Это неоднозначная территория.
На сайте Bot or Not есть стихотворения, написанные роботами – при том, что люди отнесли их к авторству человека. Соответственно, можно считать, что эти алгоритмы прошли тест Тьюринга для поэзии. Компьютер должен убедить 30% людей в своей «человечности», чтобы пройти тест. Но писатель Оскар Шварц, создатель Bot or Not, отмечает что это игра не в одни ворота: мы не только можем перепутать написанное ботом с работой человека, но и наоборот — принимаем творчество людей за творчество роботов. Возникает смешение уровней, новое понимание текстов и смыслов, где стирается грань между иллюзией и аутентичностью в привычном нам виде.
Творчество — это эмоциональное воздействие
Здесь встает еще одна проблема, связанная с сутью художественного произведения: чем оно отличается от копирования и воспроизведения прошлого опыта.Американский психолог Колин Мартиндейл (Colin Martindale) предложил оригинальную теорию креативности. Согласно его исследованиям, первоочередная цель творца — вызвать в потребителе эмоциональное возбуждение. Этого можно достичь разными средствами: новизной, сложностью идей, интеллектуальным вызовом, двусмысленностью и неоднозначностью трактовок и посылов. Социум, в котором уровень возбуждения перестает расти (или начинает убывать) — деградирует.
Мартиндейл выделил два этапа познавательного процесса. Первичный процесс — ненаправленное, иррациональное мышление вроде сновидений или мечтаний. Вторичный процесс — осознанный, концептуальный, это решение конкретных задач и использование логики. Похожую оптику он приложил и к творческому процессу: концептуальное сознание может различать, может логически мыслить, но оно не способно создать или вывести что-то, чего не знало раньше, ex nihilo nihil fit — «из ничего ничто не происходит». Изначальное мышление может проводить аналогии, выстраивать цепочки ассоциации и сравнивать, порождая новые комбинации ментальных элементов. Оно производит сырье, которое концептуальное мышление может обработать.
По близкому принципу работает описанная выше сеть GAN — одна нейросеть «различает», другая — «сравнивает и находит ассоциации». Алгоритм следует теории креативности, производит новые полотна, провоцирующие эмоциональный отклик в людях.
Нейросети — в помощь художнику. И музыканту
Искусство и технологии всегда пересекались и подпитывали друг друга (достаточно вспомнить об эпохе Возрождения, об экспериментах Леонардо и Микеланджело). Новые материалы, подходы и изобретения часто позволяли художникам создавать шедевры и целые виды искусства. Так и сегодня, помимо самостоятельного «производства» поэм, картин и музыки, нейросети помогают ученым проводить исследования в творческой сфере.Развитие современной музыкальной индустрии ориентируется на классифицированные паттерны, помогающие в буквальном смысле построить математическую модель музыки и «запрограммировать» желаемый эффект от прослушивания композиции.
Международная исследовательская группа из университетов Японии и Бельгии в сотрудничестве с компанией Crimson Technologies выпустила специальное устройство на базе машинного обучения, умеющее выявлять эмоциональное состояние слушателей и генерировать на основании собранной информации принципиально новый контент.
«Как правило, машины и программы для создания песен зависят напрямую от автоматических композиционных систем, их предварительно заданный и хранящийся объем готового музыкального материала позволяет сочинять только похожие между собой треки», — отмечает профессор Масаюки Нумао (Numao Masayuki) из Университета Осаки.
Нумао и его команда хотят предоставить «машинам» информацию об эмоциональном состоянии человека. По их мнению, это должно способствовать увеличению интерактивности музыкального опыта. Ученые провели эксперимент, во время которого испытуемые слушали музыку в наушниках с сенсорами активности головного мозга. Сведенные воедино данные ЭЭГ транслировались роботу-композитору. В результате удалось выявить большую вовлеченность и более интенсивную эмоциональную реакцию слушателей на определенную музыку.
Нумао считает, что эмоционально-связанные интерфейсы имеют потенциал: «Например, мы можем использовать их в здравоохранении, чтобы мотивировать человека чаще упражняться или же просто приободрить его, поднять настроение».
Искусство видеть
Джон Бергер (Бёрджер) в «Искусстве видеть» отмечал, что зрение для человека первично по отношению к языку. Знание влияет на нашу оценку. По Бергеру, любое изображение — это просто один из многочисленных способов видения, но наше восприятие изображения зависит от того, каким способом видения пользуемся мы.Поэтому дискуссия о творчестве алгоритмов мотивирует нас задуматься не только о том, как «творят» программы, но и о том, как мы сами воспринимаем творчество. Нейросети могут писать стихи, а мы порой путаем их с человеческими: но именно наше восприятие, наше прочтение наполняет их смыслом. Например, для алгоритма слова, мазки, цвета и звуки являются всего лишь набором знаков, которые он может сложить в гармоничную структуру. Это сырье, за которым робот не видит содержания, смыслового поля. По крайней мере, пока не видит.
Роботы не могут придать предметам значение, а произведениям — глобальную культурную ценность. «Никогда еще не писалось так много стихов и так мало поэзии», – читаем у Умберто Эко. ИИ может создать гениальную симфонию или сочетание рифм, правильно организованных графически, но лишь признание человека позволит всему этому обрести столь желаемый многими статус – действительно быть искусством, а не казаться им.
habr.com
Рисунки нейронных сетей | Фото | ИноСМИ
Нейросети, с помощью которых распознаются изображения, состоят из 10-30 связанных слоев. В процессе их работы изображение «угадывается» постепенно: сначала распознаются общие формы, границы и углы, затем система определяет предмет на основании собранных особенностей и затем делает вывод об объекте, который может состоять их таких деталей. Например, нейросеть «видит» округлые объекты зеленого цвета, они напоминает ей листья, скопление листьев говорит о том, что на фотографии изображено дерево. Эксперимент же заключался в том, чтобы перевернуть работу нейросети «с ног на голову» и заставить ее находить изображения в абстракциях и белом шуме.
Нейронные сети обучаются на большом количестве примеров. Например, чтобы знать, что представляет собой то же самое дерево, системе нужно скормить несколько тысяч разных изображений деревьев. Только увидев дерево в тысячах разных варианотов, она сможет понять, что это такое и научится выделять особенности, присущие именно деревьям.
В эксперименте инженеры показали нейросети изображения, близкие к белому шуму, и предложили найти в них различные объекты. Иногда нейросеть просили найти что-то определенное, иногда давали свободу творчества. Здесь, например, систему попросили нарисовать банан, и в некоторых скоплениях точек нейросеть увидела сходства с бананом.
В любой картинке система будет усиливать хорошо знакомые ей черты. Нейросеть, которую тренировали на распознавание животных, будет всюду видеть черты глаза и мордочки, а натренированная, к примеру, на восточную архитектуру, преобразует абстракции в пагоды и храмы.
То, какое у системы получится изображение, зависит от выбранного для распознавания слоя. Базовые слои найдут только общие формы и простые геометрические фигуры (как на фотографии с антилопами выше), зато более высокие увидят на любой фотографии сложные объекы. Вот что, например, нейросеть увидела на фотографии облаков.
Примеры преобразования изображений системой: линия горизонта превращается в башни и пагоды, деревья – в здания, листья – в птиц и насекомых.
В горном пейзаже система увидела архитектурный ансамбль.
Различные орнаменты, увиденные системой.
Система ищет знакомые черты в картине Жоржа Сёра.
С помощью нескольких итераций инженерам удалось получить сложные абстрактные картины с множеством деталей. В этом случае нейронной сети несколько раз отдавали картинку, нарисованную ей самой. В основе мог быть тот же белый шум.
Рисунок, полученный с помощью нескольких итераций.
Рисунок, полученный с помощью нескольких итераций.
Рисунок, полученный с помощью нескольких итераций.
Рисунок, полученный с помощью нескольких итераций.
Рисунок, полученный с помощью нескольких итераций.
Рисунок, полученный с помощью нескольких итераций.
Нейрофизиологи отмечают, что система распознавания образов мозгом устроена схожим образом.
inosmi.ru









